Feedback
Custom backup location¶
This guide introduces a feature of CrateDB Cloud on Kubernetes that lets users specify their backup location. This gives you full ownership and control of your data when using CrateDB Cloud on Kubernetes.
Prerequisites¶
This guide describes only the final deployment stage of the CrateDB Cloud on Kubernetes cluster. For the full instructions, see either the Self-hosted Edge, or the Managed Edge tutorials.
The custom backup location only supports Amazon S3 bucket or S3-compatible storage.
Configuration¶
If you’re using an Amazon S3 bucket, you will need the Access Key ID and the Secret Access Key of the user that has access to the bucket that you want to backup your data to.
If you’re using non-Amazon S3 storage, you will also need to specify an endpoint URL of the storage.
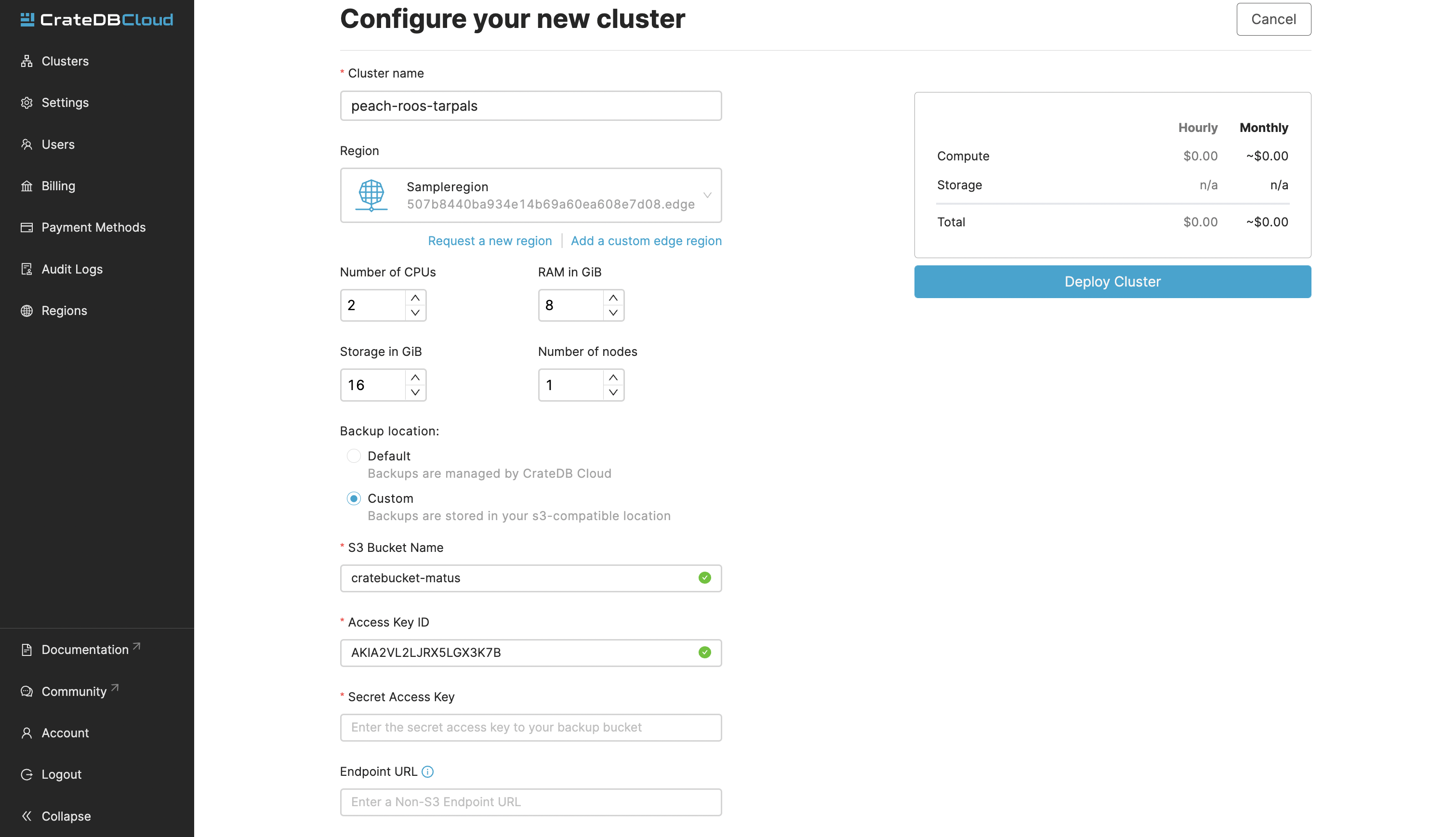
After you have put in your details, you can deploy the cluster.
Your cluster will now automatically backup to your storage every hour. You can also make a manual backup with COPY TO statement.
Note
If you plan to do manual backups of certain files often, we encourage you to enable the bucket versioning. That way, you can access older revisions of the saved files.