Feedback
CrateDB multi-node setup¶
CrateDB can run on a single node. However, in most environments, CrateDB is run as a cluster of three or more nodes.
For development purposes, CrateDB can auto-bootstrap a cluster when you run all nodes on the same host. However, in production environments, you must configure the bootstrapping process manually.
This guide shows you how to bootstrap (set up) a multi-node CrateDB cluster using different methods.
Table of contents
Cluster bootstrapping¶
Starting a CrateDB cluster for the first time requires the initial list of master-eligible nodes to be defined. This is known as cluster bootstrapping.
This process is only necessary the first time a cluster starts because:
nodes that are already part of a cluster will remember this information if the cluster restarts
new nodes that need to join a cluster will obtain this information from the cluster’s elected master node
Single-host auto-bootstrapping¶
If you start up several nodes (with default configuration) on a single host, the nodes will automatically discover one another and form a cluster. This does not require any configuration.
If you want to run CrateDB on your local machine for development or experimentation purposes, this is probably your best option.
Caution
For better performance and resiliency, production CrateDB clusters should be run with one node per host machine. If you use multiple hosts, you must manually bootstrap your cluster.
Warning
If you start multiple nodes on different hosts with auto-bootstrapping enabled, you cannot, at a later point, merge those nodes together to form a single cluster without the risk of data loss.
If you have multiple nodes running on different hosts, you can check whether they have formed independent clusters by visiting the Admin UI (which runs on every node) and checking the cluster browser.
If you end up with multiple independent clusters and instead want to form a single cluster, follow these steps:
Shut down all the nodes
Completely wipe each node by deleting the contents of the
datadirectory under CRATE_HOMEFollow the instructions in manual bootstrapping)
Restart all the nodes and verify that they have formed a single cluster
Restore your data
Tarball installation¶
If you are installing CrateDB using the tarball method, you can start a single-host three-node cluster with auto-bootstrapping by following these instructions.
Unpack the tarball:
sh$ tar -xzf crate-*.tar.gz
It is common to configure the metadata gateway so that the cluster waits for all data nodes to be online before starting the recovery of the shards. In this case let’s set gateway.expected_data_nodes to 3 and gateway.recover_after_data_nodes also to 3. You can specify these settings in the configuration file of the unpacked directory.
Note
Configuring the metadata gateway is a safeguarding mechanism that is useful for production clusters. It is not strictly necessary when running in development. However, the Admin UI will issue warnings if you have not configured the metadata gateway.
See also
The metadata gateway section includes examples.
Copy the unpacked directory into a new directory, three times, one for each node. For example:
sh$ cp -R crate-*/ node-01 sh$ cp -R crate-*/ node-02 sh$ cp -R crate-*/ node-03
Tip
Each directory will function as CRATE_HOME for that node
Start up all three nodes by changing into each node directory and running the bin/crate script.
Caution
You must change into the appropriate node directory before running the bin/crate script.
When you run bin/crate, the script sets CRATE_HOME to your current directory. This directory must be the root of a CrateDB installation.
Tip
Because you are supposed to run bin/crate as a daemon (i.e., a long-running process), the most straightforward way to run multiple nodes for testing purposes is to start a new terminal session for each node. In each session, change into the appropriate node directory, run bin/crate, and leave this process running. You should now have multiple concurrent bin/crate processes.
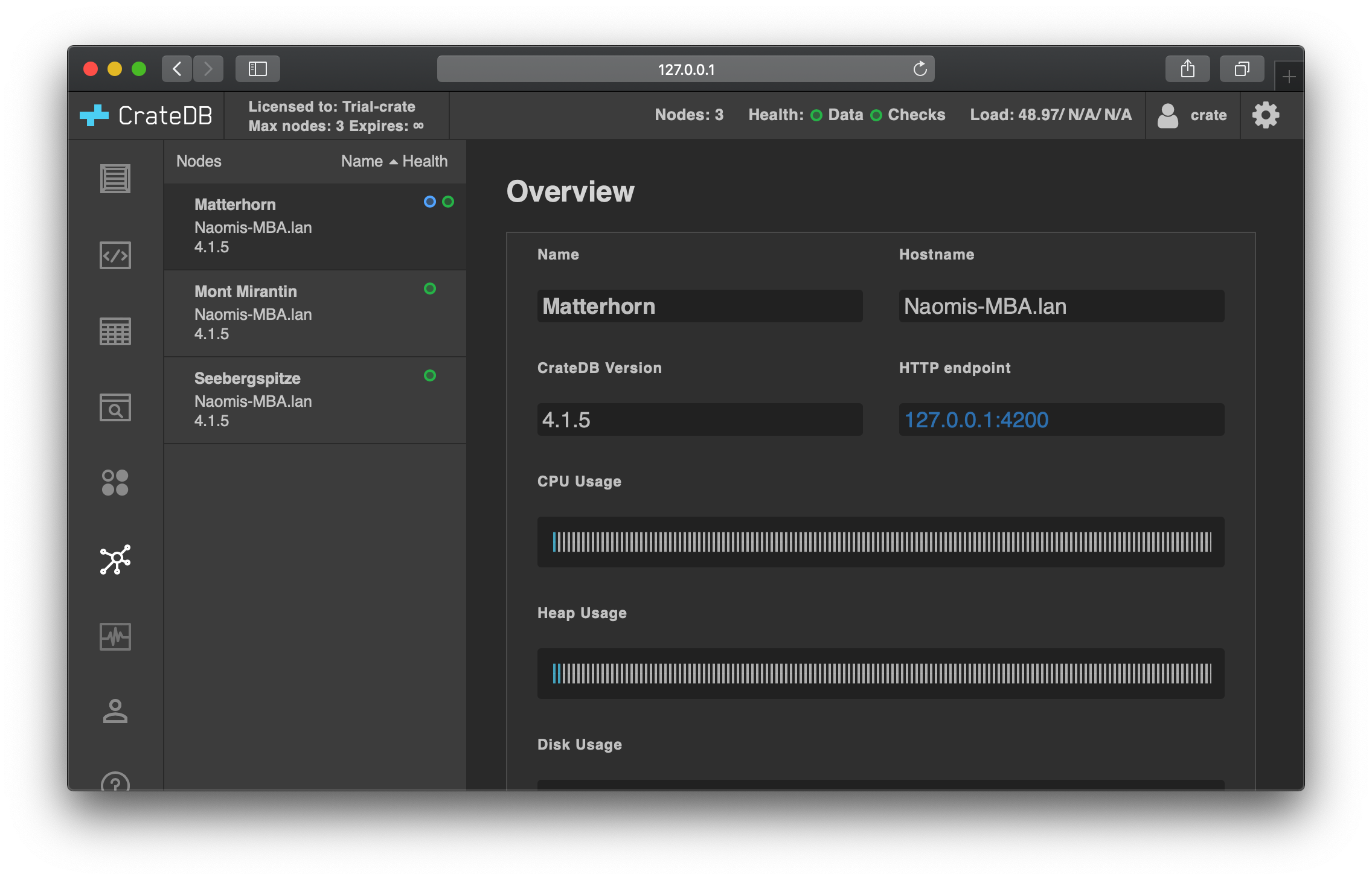
Visit the Admin UI on one of the nodes. Check the cluster browser to verify that the cluster has auto-bootstrapped with three nodes. You should see something like this:
Manual bootstrapping¶
To run a CrateDB cluster across multiple hosts, you must manually configure the bootstrapping process by telling nodes how to:
Elect a master node the first time
You can also configure the metadata gateway (as with auto-bootstrapping).
Node discovery¶
Seeding manually¶
With CrateDB 4.x and above, you can configure a list of nodes to seed the
discovery process with the
discovery.seed_hosts setting in your
configuration file. This setting should contain one identifier per
master-eligible node. For example:
discovery.seed_hosts:
- node-01.example.com:4300
- 10.0.1.102:4300
- 10.0.1.103:4300
Alternatively, you can configure this at startup with a command-line option. For example:
sh$ bin/crate \
-Cdiscovery.seed_hosts=node-01.example.com,10.0.1.102,10.0.1.103
Note
You must configure every node with a list of seed nodes. Each node discovers the rest of the cluster via the seed nodes.
Tip
If you are using CrateDB 3.x or below, you can use the
discovery.zen.ping.unicast.hosts setting instead of
discovery.seed_hosts.
Unicast host discovery¶
Instead of configuring seed hosts manually (as above), you can configure CrateDB to fetch a list of seed hosts from an external source.
The currently supported sources are:
-
To enable DNS discovery, configure the
discovery.seed_providerssetting in your configuration file tosrv:discovery.seed_providers: srv
CrateDB will perform a DNS query using SRV records and use the results to generate a list of unicast hosts for node discovery.
-
To enable Amazon EC2 discovery, configure the
discovery.seed_providerssetting in your configuration file:discovery.seed_providers: ec2
CrateDB will perform an Amazon EC2 API query and use the results to generate a list of unicast hosts for node discovery.
Microsoft Azure
Warning
Microsoft Azure discovery was deprecated in CrateDB 5.0.0 and removed in 5.1.0.
To enable Microsoft Azure discovery, configure the
discovery.seed_providerssetting in your configuration file:discovery.seed_providers: azure
CrateDB will perform an Azure Virtual Machine API query and use the results to generate a list of unicast hosts for node discovery.
Master node election¶
The master node is responsible for making changes to the global cluster state. The cluster elects the master node from the configured list of master-eligible nodes the first time a cluster is bootstrapped. This is not necessary if nodes are added later or are restarted.
In development mode, with no discovery settings configured, master election is performed by the nodes themselves, but this auto-bootstrapping is designed to aid development and is not safe for production. In production you must explicitly list the names or IP addresses of the master-eligible nodes whose votes should be counted in the very first election.
If initial master nodes are not set, then new nodes will expect to be able to discover an existing cluster. If a node cannot find a cluster to join, then it will periodically log a warning message indicating that the master is not discovered or elected yet.
You can define the initial set of master-eligible nodes with the cluster.initial_master_nodes setting in your configuration file. This setting should contain one identifier per master-eligible node. For example:
cluster.initial_master_nodes:
- node-01.example.com
- 10.0.1.102
- 10.0.1.103
Alternatively, you can configure this at startup with a command-line option. For example:
sh$ bin/crate \
-Ccluster.initial_master_nodes=node-01.example.com,10.0.1.102,10.0.1.10
Warning
You do not have to configure cluster.initial_master_nodes on every node. However, you must configure cluster.initial_master_nodes identically whenever you do configure it, otherwise CrateDB may form multiple independent clusters (which may result in data loss).
CrateDB requires a quorum of nodes before a master can be elected. A quorum ensures that the cluster does not elect multiple masters in the event of a network partition (also known as a split-brain scenario).
CrateDB (versions 4.x and above) will automatically determine the ideal quorum size, but if you are using CrateDB versions 3.x and below, you must manually set the quorum size using the discovery.zen.minimum_master_nodes setting and for a three-node cluster, you must declare all nodes to be master-eligible.
Metadata gateway¶
When running a multi-node cluster, you can configure the metadata gateway settings so that CrateDB delays recovery until a certain number of nodes is available. This is useful because if recovery is started when some nodes are down CrateDB will proceed on the basis the nodes that are down may not be coming back, and it will create new replicas and rebalance shards as necessary. This is an expensive operation that, depending on the context, may be better avoided if the nodes are only down for a short period of time. So, for instance, for a three-nodes cluster, you can decide to set gateway.expected_data_nodes to 3, and gateway.recover_after_data_nodes also to 3.
You can specify both settings in your configuration file:
gateway:
recover_after_data_nodes: 3
expected_data_nodes: 3
Alternatively, you can configure these settings at startup with command-line options:
sh$ bin/crate \
-Cgateway.expected_data_nodes=3 \
-Cgateway.recover_after_data_nodes=3
See also
Other settings¶
Cluster name¶
The cluster.name setting allows you to create multiple separate clusters. A node will refuse to join a cluster if the respective cluster names do not match.
By default, CrateDB sets the cluster name to crate for you.
You can override this behavior by configuring a custom cluster name using the cluster.name setting in your configuration file:
cluster.name: my_cluster
Alternatively, you can configure this setting at startup with a command-line option:
sh$ bin/crate \
-Ccluster.name=my_cluster
Node name¶
If you are manually bootstrapping a cluster, you must specify a list of master-eligible nodes (see above). To do this, you must refer to nodes by node name, hostname, or IP address.
By default, CrateDB sets the node name to a random value from the Summits table.
You can override this behavior by configuring a custom node name using the node.name setting in your configuration file. For example:
node.name: node-01
Alternatively, you can configure this setting at startup with a command-line option:
sh$ bin/crate \
-Cnode.name=node-01
Master-eligibility¶
If you are manually bootstrapping a cluster, any
nodes you list as master-eligible must have a
node.master value of true. This is the default value.
Inter-node communication¶
By default, CrateDB nodes communicate with each other on port 4300. This
port is known as the transport port, and it must be accessible from every
node.
If you prefer, you can specify a port range instead of a single port number. Edit the transport.tcp.port setting in your configuration file:
transport.tcp.port: 4350-4360
Tip
If you are running a node on Docker, you can configure CrateDB to publish the container’s external hostname and the external port number bound to the transport port. You can do that in your configuration file using the network.publish_host and transport.publish_port settings.
For example:
# External access
network.publish_host: node-01.example.com
transport.publish_port: 4321
See also