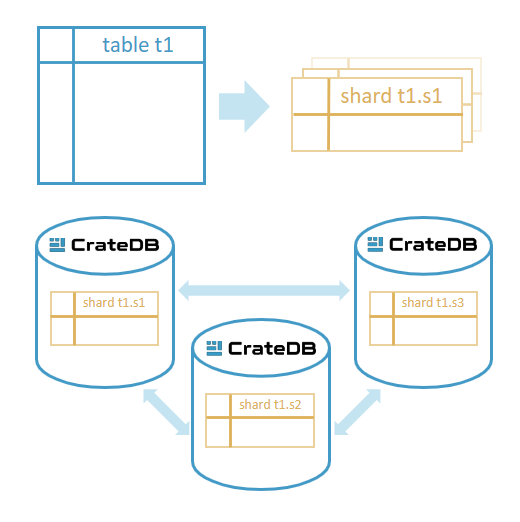
CrateDB automatically divides data into smaller units called shards, which are distributed across all nodes in a cluster.
This approach, known as sharding, enables CrateDB to process data in parallel, achieve linear scalability, and maintain high performance even as data volumes or workloads grow. Each shard acts as an independent data container, storing a portion of a table’s data. When you query the table, CrateDB’s distributed SQL engine executes operations across all relevant shards simultaneously and merges the results, ensuring fast, efficient, and predictable response times.
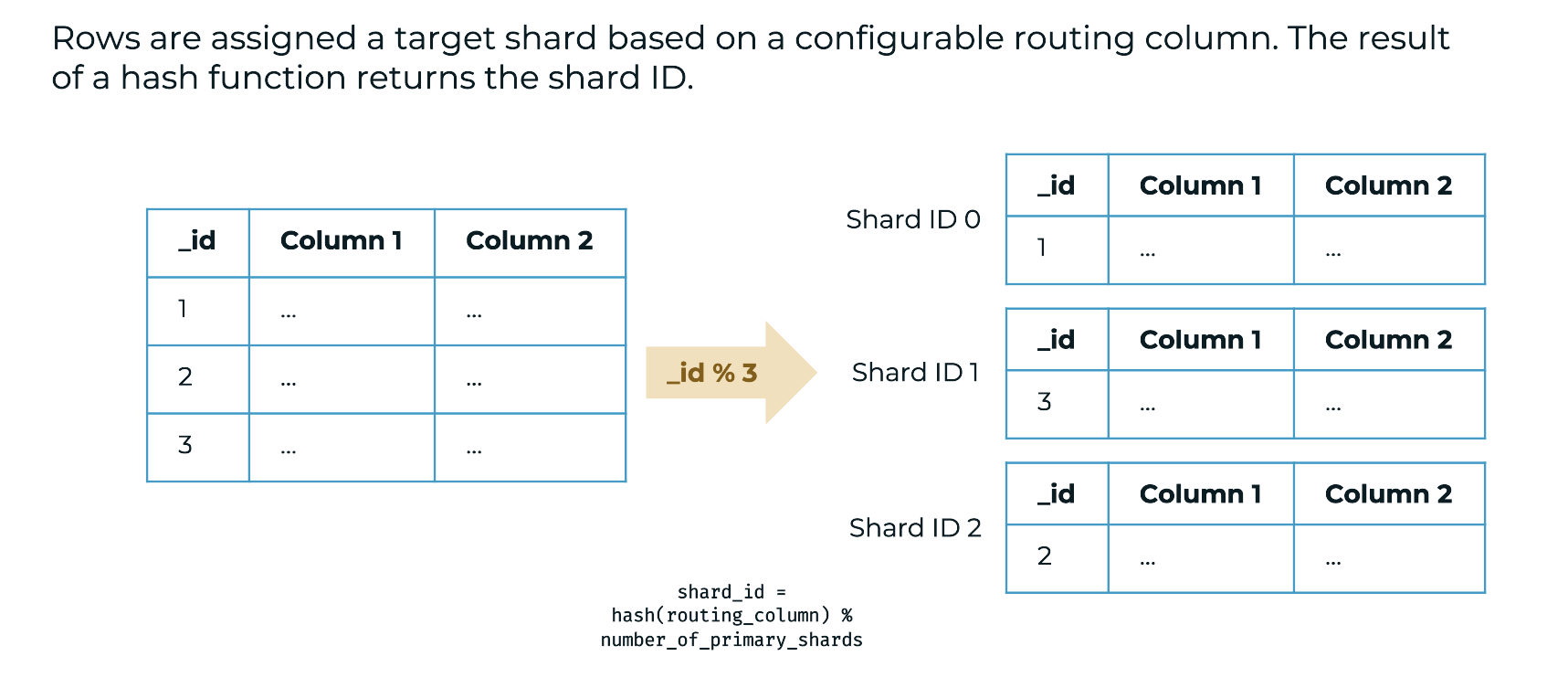
How sharding works
When data is inserted, CrateDB automatically determines which shard it belongs to and places it on the appropriate node.
- Automatic distribution: By default, CrateDB sets the number of shards based on the cluster’s size and hardware configuration.
- Dynamic balancing: When nodes are added, removed, or become overloaded, CrateDB automatically redistributes shards to maintain a balanced cluster.
- Independent storage: Each shard is fully self-contained, with its own indexing and data files.
- Fault isolation: If a node fails, only the shards on that node are affected, replicas on other nodes ensure continuity.

Optimizing shard configuration
Choosing the right number of shards per table is key to optimizing performance and resource utilization.
- Best practice: Ideally, each table should have the same number of shards per node as the number of available CPUs on that node.
- Default behavior: If the shard count is not defined, CrateDB automatically determines an optimal value based on the cluster’s hardware (typically the number of CPU cores).
- Advanced tuning: In very heavy read/write environments, you can use advanced configurations, such as defining dedicated master-eligible nodes that hold cluster metadata but not data, to prevent bottlenecks and maintain performance stability.
Sharding and partitioning
Sharding works seamlessly with partitioning, allowing you to distribute data within logical time or value-based segments. For example:
- A time-series table can be partitioned by month and each partition can have a different shard count to handle variable load.
- As data grows, newer partitions can be created with more shards to leverage additional nodes or CPU capacity.
Benefits of sharding
- Linear scalability: Scale out simply by adding nodes; CrateDB distributes data and queries automatically.
- Performance balance: Automatic rebalancing ensures even workload distribution and optimal cluster efficiency.
- Resilience: Shard-level isolation reduces the blast radius of node or hardware failures.
- Operational simplicity: No manual redistribution or reconfiguration is needed as data or cluster size changes.
- Predictable growth: Adjust shard and partition strategies over time without downtime or redesign.


