In this step-by-step post, I introduce a method to get financial data from stock companies. Then, I show how to store this data in CrateDB and keep it up to date with companies’ data.
This tutorial will teach you how to automatically collect historical data from S&P-500 companies and store it all in CrateDB using Python.
tl;dr: I will go through how to:
- Import S&P-500 companies’ data with the Yahoo! Finance API into a Jupyter Notebook,
- Set up a connection to CrateDB with Python,
- Create functions to create tables, insert values, and retrieve data from CrateDB,
- Upload finance market data into CrateDB
Setting up CrateDB, Jupyter, and Python
CrateDB
If you’re new to CrateDB and want to get started quickly and easily, a great option is to try the Free Tier in CrateDB Cloud. With the Free Tier, you have a limited Cluster that is free forever; no payment method is required. Now, if you are ready to experience the full power of CrateDB Cloud, take advantage of the 200$ in free credits to try the cluster of your dreams.
To start with CrateDB Cloud, navigate to the CrateDB website and follow the steps to create your CrateDB Cloud account. Once you log in to the CrateDB Cloud UI, select Deploy Cluster to create your free cluster, and you are ready to go!
With my CrateDB Cluster up and running, I can ensure Python is set up.
Python
Python is a good fit for this project: it’s simple, highly readable, and has valuable analytics libraries for free. I download Python, then reaccess the terminal to check if Python was installed and which version I have with the command pip3 --version, which tells me I have Python 3.9 installed.
All set!
Jupyter
The Jupyter Notebook is an open-source web application that creates and shares documents containing live code, equations, visualizations, and narrative text.
A Jupyter Notebook is an excellent environment for this project. It contains executable documents (the code) and human-readable documents (tables, figures, etc.) in the same place!
I follow the Jupiter Installation tutorial 2 for the Notebook, which is quickly done with Python and the terminal commandpip3 install notebook and now I run the Notebook (using Jupyter 1.0.0) with the command jupyter notebook
Setup done!
Now I can access my Jupyter Notebook by opening the URL printed in the terminal after running this last command. In my case, it is at http://localhost:8888/
Creating a Notebook
On Jupyter’s main page, I navigate to the New button on the top right and select Python 3 (ipykernel)
An empty notebook opens.
To make sure everything works before starting my project:
- I call the notebook “financial-data-with-cratedb”,
- I write a ‘Hello World!’ line with
- run the code snippet by pressing
Alt + Enter(or clicking on the Run button)
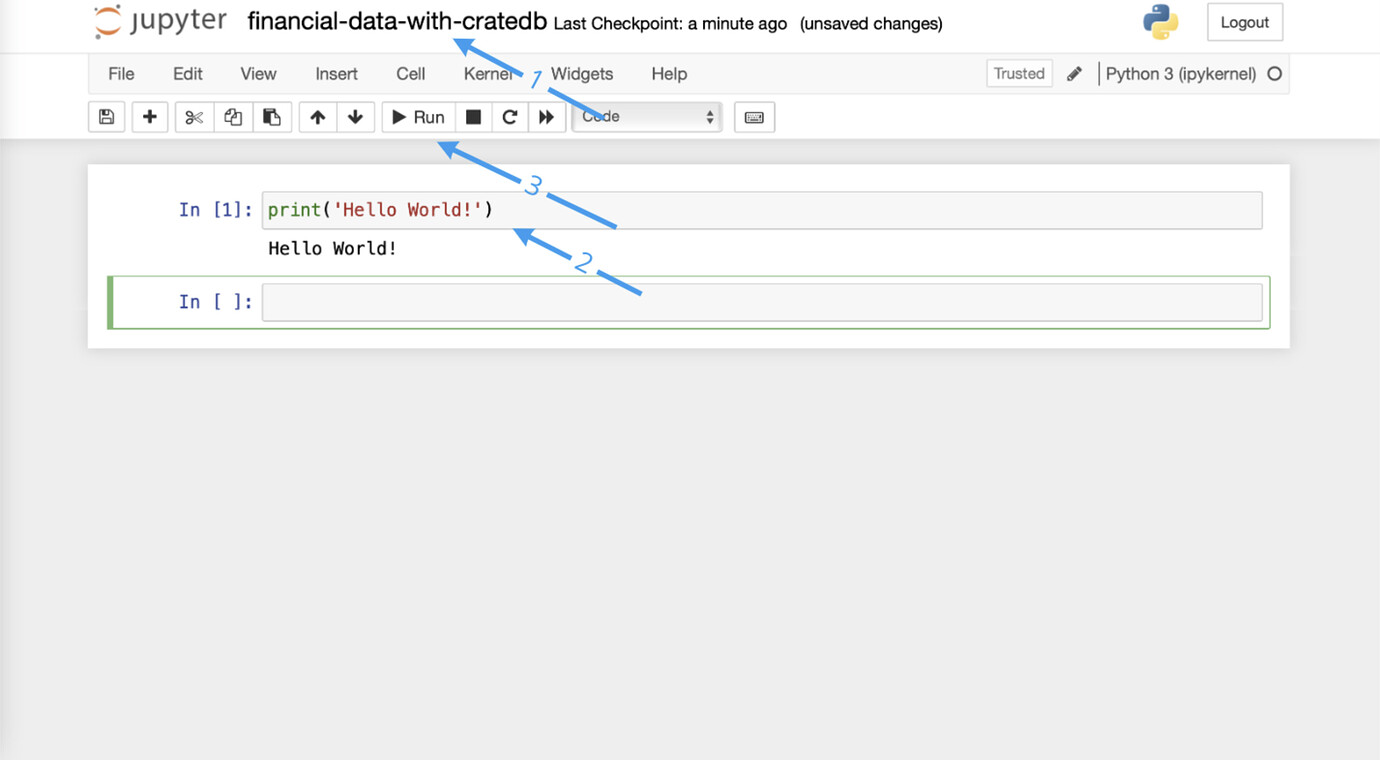
Great, it works! Now I can head to the following steps to download the financial data.
Getting all S&P-500 ticker symbols from Wikipedia
When I read yfinance documentation (version 0.1.63), I find the history function, which gets a ticker symbol as a parameter and downloads the data from this company.
I want to download data from all S&P-500 companies, so having a list with all their symbols would be perfect.
I then found a tutorial by Edoardo Romani, which shows how to get the symbols from the List of S&P-500 companies’ Wikipedia page and store them in a list.
So, in my Notebook, I import BeautifulSoup 4.10.0 and requests 2.26.0 to pull out HTML files from Wikipedia and create the following function:
What this function does is:
- it finds the S&P-500 companies table components in the Wikipedia page’s HTML code
- it extracts the table rows from the components and stores it in the
data_rowsvariable - it splits
data_rowsinto thestocklist, where each element contains information about one stock (Symbol, Security, SEC filings, …) - it takes the Symbol for each stock list element and adds it to the
tickerslist - finally, it sorts the
tickerslist in alphabetical order and returns it
To check if it works, I will call this function and print the results with
and it looks like this:
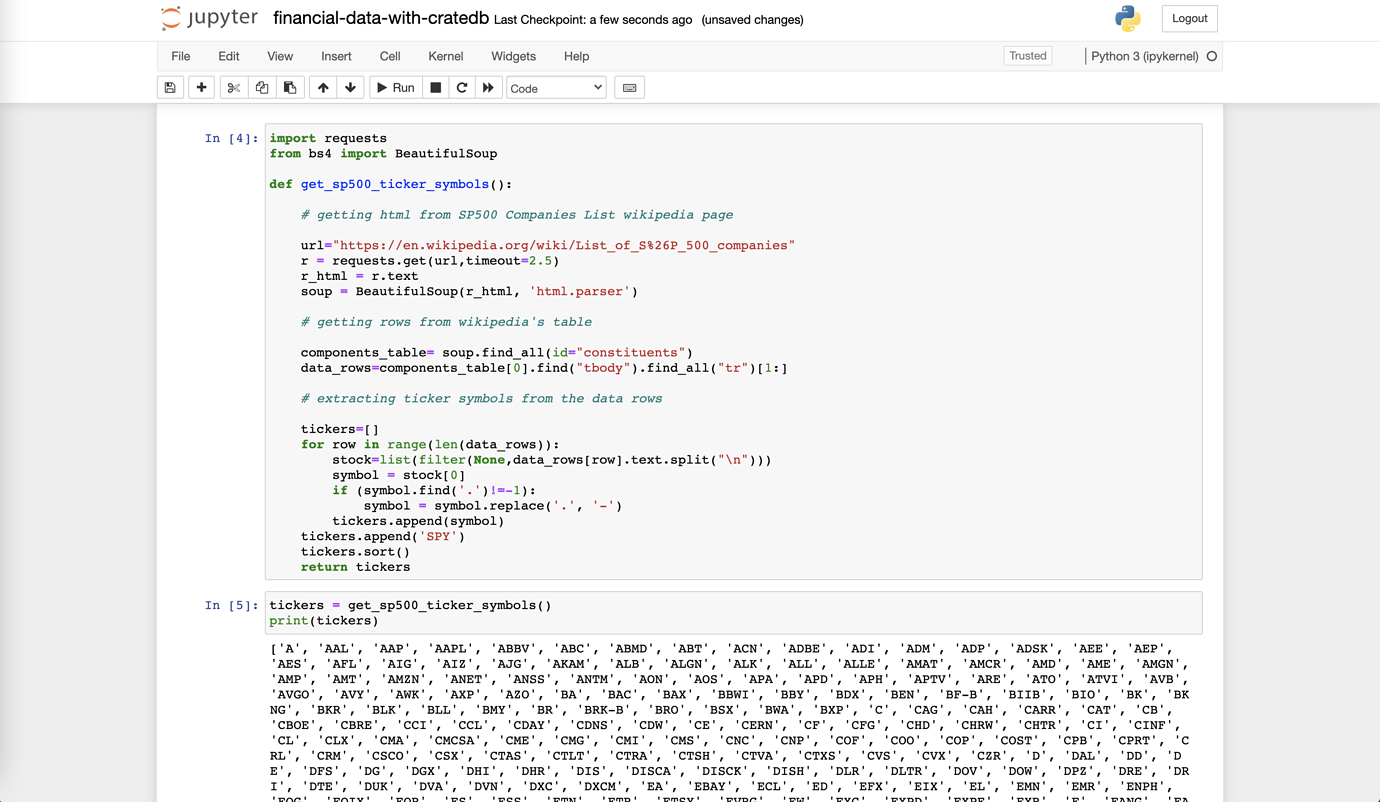
Now that I have a list of all the stock tickers, I can move on and download their data with yfinance.
Downloading financial data with finance
Pandas is a famous package in Python, often used for Data Science. It shortens the process of handling data, has complete yet straightforward data representation forms, and makes tasks like filtering data easy.
Its key data structure is called a DataFrame, which allows storage and manipulation of tabular data: in this case, the columns are going to be the financial variables (such as “date”, “ticker”, “closing price”…) and the rows are going to be filled with data about the S&P-500 companies.
So, the first thing I do is import the yfinance(0.1.63) and pandas(2.0.0)
And now, I have designed a function to download the data from a company from a given period.
First, I create a data DataFrame to store the stocks’ closing_date, ticker, and close_value.
I get the data from the ticker on that period with the Ticker.history function from yfinance. I store the result in the history DataFrame, rename the index (which contains the date) to closing_date, as this is the column name I prefer for CrateDB, and then reset the index. Instead of having the date as the index, I have a column called closing_date, which has the date information, and the rows are indexed trivially (like 0, 1, 2, …). I also add a ticker column containing the current ticker and rename the Close column to match the close_value name in the data DataFrame. Finally, I add the closing_date, ticker, and close_value data for that ticker to my data DataFrame.
The function returns the data DataFrame containing the closing_date, ticker, and close_value data for the given ticker over the period.
This is what download_data looks like:
To check if everything works, I execute the function and store it in the my_data variable, and print the result:
and it looks like this: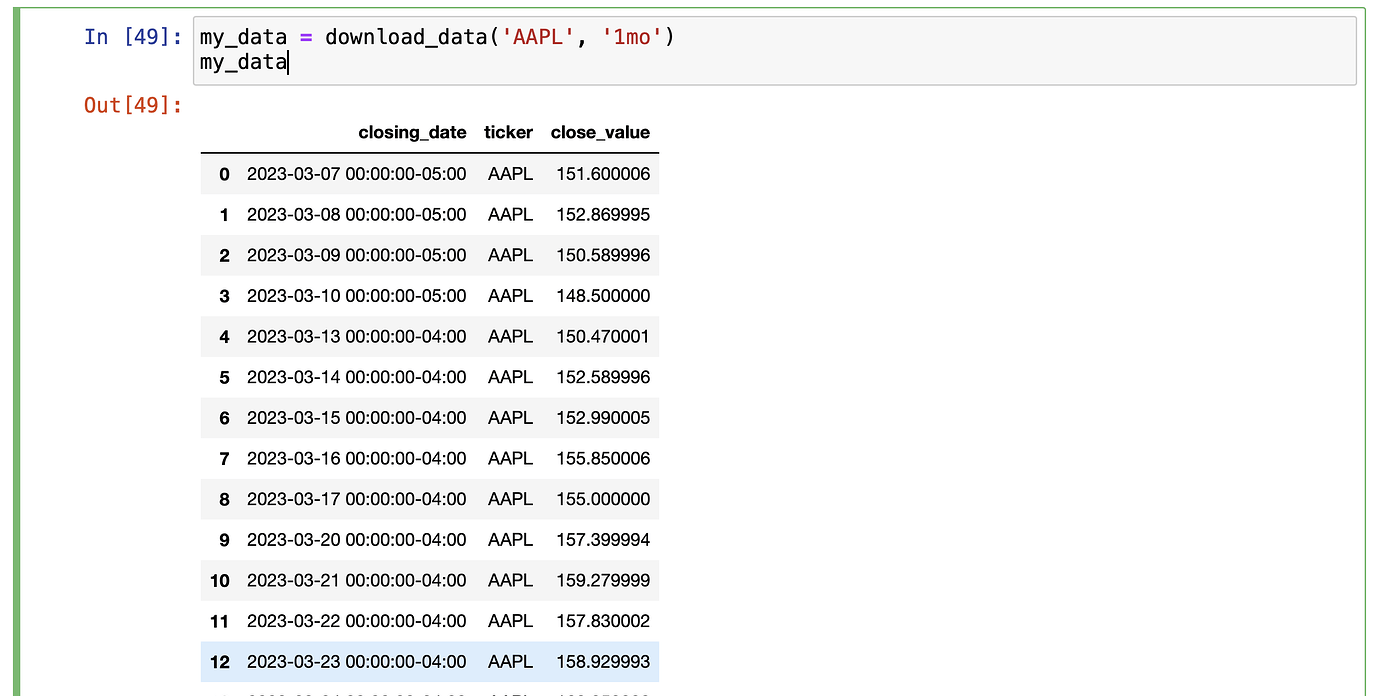
Connecting to CrateDB
In the Overview tab of my CrateDB Cloud Cluster I find several ways to connect to CrateDB with CLI, Python, JavaScript, among others. So I select the Python option and choose one of the variants, such as psycopg2(version 2.9.1).
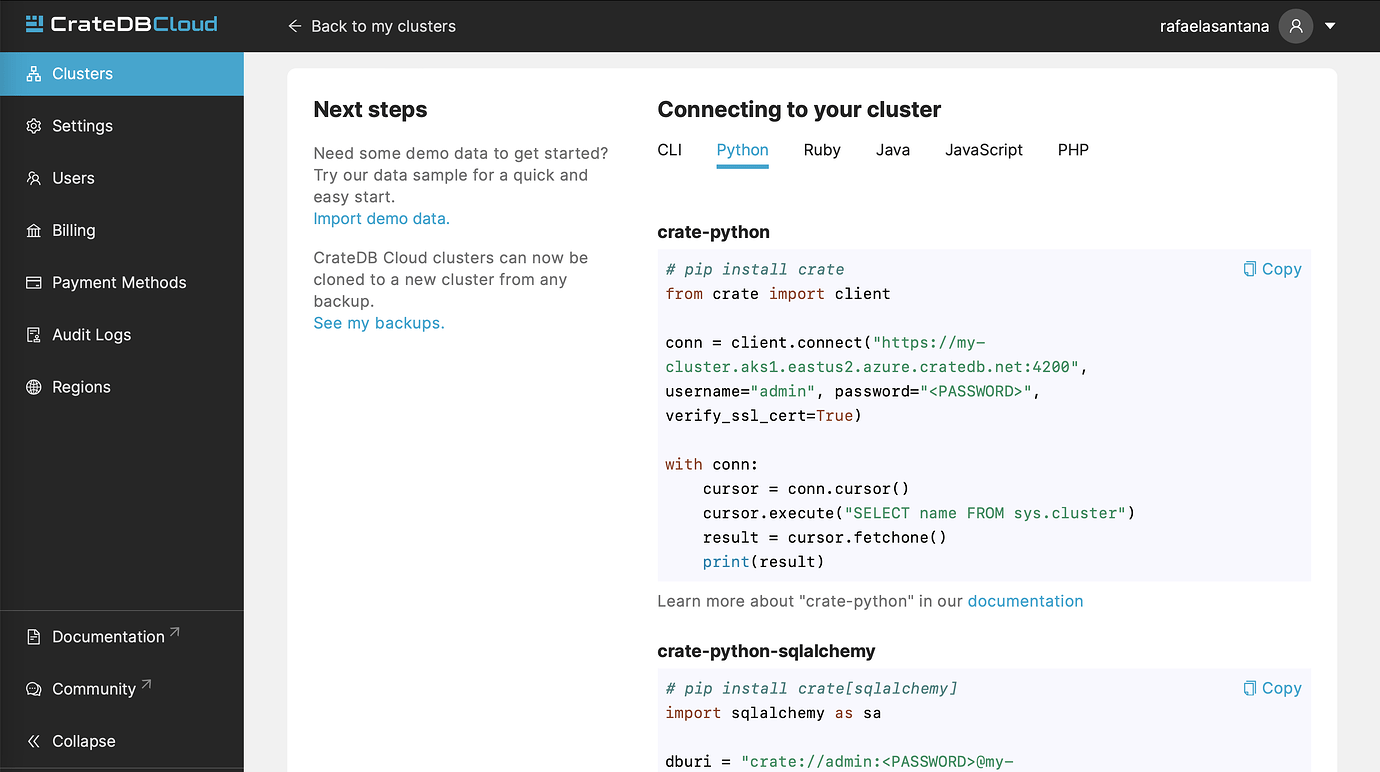
I copy the code to connect and add my password to it in the <PASSWORD> field. It creates a conn variable, which stores the connection, and a cursor variable, which allows Python code to execute PostgreSQL commands. I adapt the code slightly so I leave the cursor open to use it later on. It then looks like this:
When I run this code it prints ('my-cluster',), which is the name I have to my cluster, so the connection works!
Now I can create more functions to create tables in CrateDB, insert my data values into a table, and retrieve data!
Creating functions for CrateDB
Creating table
I will have the closing_date, ticket, and close_value columns in my table. Also, I want to give the table name as a parameter and only create a new table in case the table does not exist yet. I use the SQL keywords CREATE TABLE IF NOT EXISTS in my function.
Now I must create the complete statement as a string and execute it with the cursor.execute command:
Inserting values into CrateDB
I want to create a function that:
- gets the table name and the data as parameters
- makes an insert statement for this data
- executes this statement
(In the next steps, I review each part of this function. However, I have a snippet of the complete function at the end of this section)
Formatting the entries is crucial for successful insertion. However, because of that, this function became rather long: so I will go through each section separately and then join them all in the end.
- Before anything else, I import the
mathmodule to use later in this function. - The function starts by creating an empty list called
values_array. This list will hold the formatted values I want to insert into the table. - Next, I loop through each row of the
dataand extract the row values using the iloc method, which returns the values of the specified row. - For each row, I check if the
close_valuevalue for that row isNaN(not a number), and if so, set it to -1. This is done to handle missing data. - Then I format the
closing_datevalue to match the timestamp format that the table expects. The date is first converted to a string in the format “YYYY-MM-DD”, then a time in the format “T00:00:00Z” is added to the end. The resulting string is then wrapped in single quotes to create a string that matches the expected timestamp format. - Finally, I create a string representing the values for this row in the format (
closing_date, ticker, close_value), and append it to the values_array list. I repeat this process for each row in thedataDataFrame.
- After all the row values have been added to the
values_arraylist, I create a new table with the specified name (if it does not already exist) using thecreate_tablefunction. - Then I create the first part of the SQL
INSERTstatement, which includes the table name and the column names we insert into (closing_date, ticker,andclose_value. This part of the statement is stored in theinsert_stmtvariable. - Next, I add the values tuples from
values_arrayto theinsert_stmt, separated by commas. The final SQLINSERTstatement is created by concatenating theinsert_stmtvariable and a semicolon at the end.
Finally, the function executes the INSERT statement using the cursor.execute() method, and prints out a message indicating how many rows were inserted into the table.
In summary, in insert_values, I take the table name and the data, format the data into a SQL INSERT statement, and insert the data into the specified table.
This is what the complete function looks like:
Now I can move on to the next function, which is quite handy regarding automation.
Selecting the last inserted Date
I want my stock market data in CrateDB to be up to date, requiring I run this script regularly.
However, I do not want to download data I already have or have duplicate entries in CrateDB.
That’s why I create this function, which selects the most recent date from the data in my CrateDB table. I will use this date to calculate the period to download data from in the download_data function: this way, this function will only download new data!
In the get_period_to_download function, I calculate the difference between today and the last inserted date and return the corresponding period.
The only thing missing is a method to wrap up everything. Let’s move on to it!
Updating the table
This method wraps up all the others.- I first get the most recent date in the table with
select_last_inserted_date - Then I calculate the period between today and this date with
get_period_to_download - I take the list of all SP 500 tickers with
get_sp500_ticker_symbols - And then, for each of these tickers, I download the data with
download_dataand insert it in CrateDB withinsert_values
This is what the final function looks like:
Final Test
I have all the necessary functions ready to work! To have a clean final test, I:
- place all the functions at the beginning of the Notebook and run their code blocks
- leave the CrateDB connection and the
update_tablecall at the end
I navigate to the CrateDB Admin UI, where I see the new table sp500 was created and that it is filled with the financial data
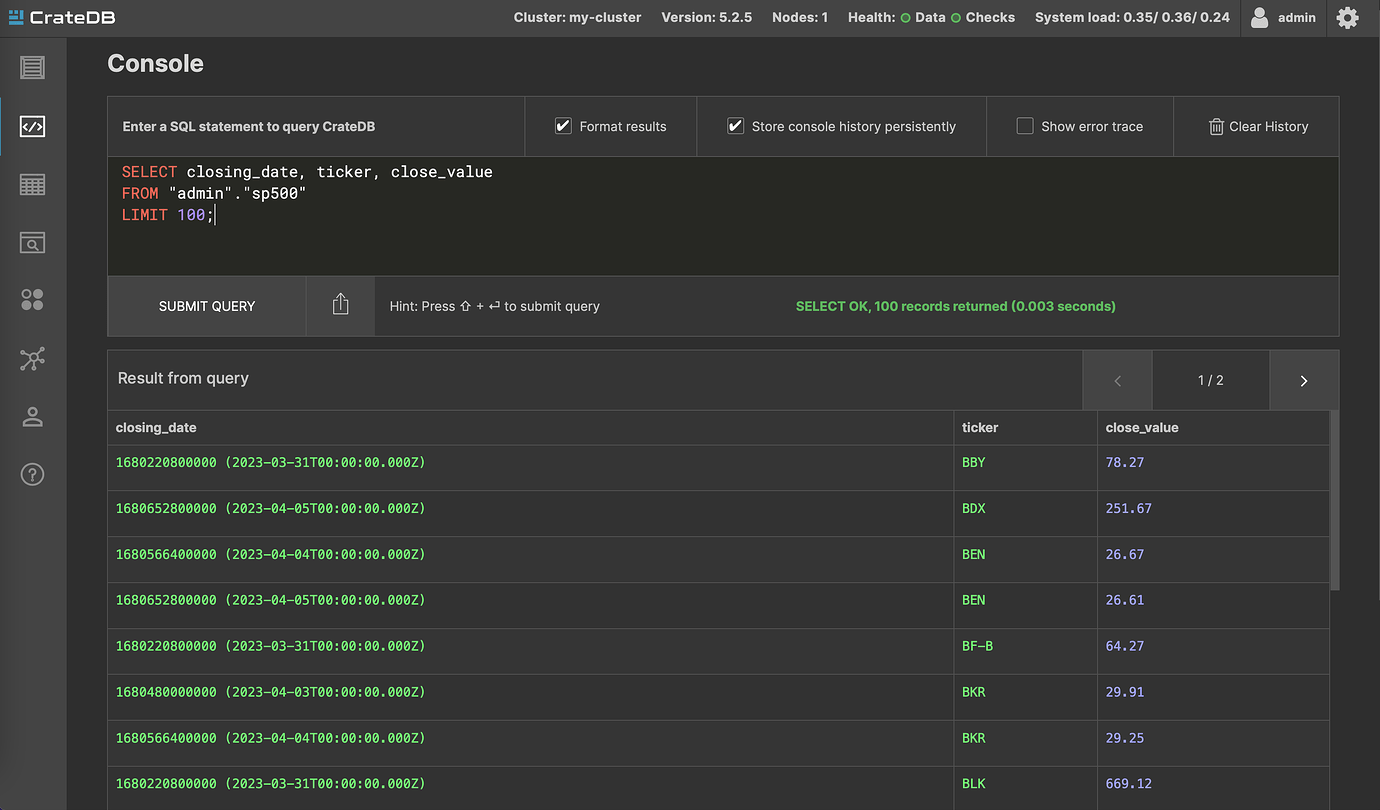
I make a simple query to get Apple’s data from my sp500 table
And instantly get the results
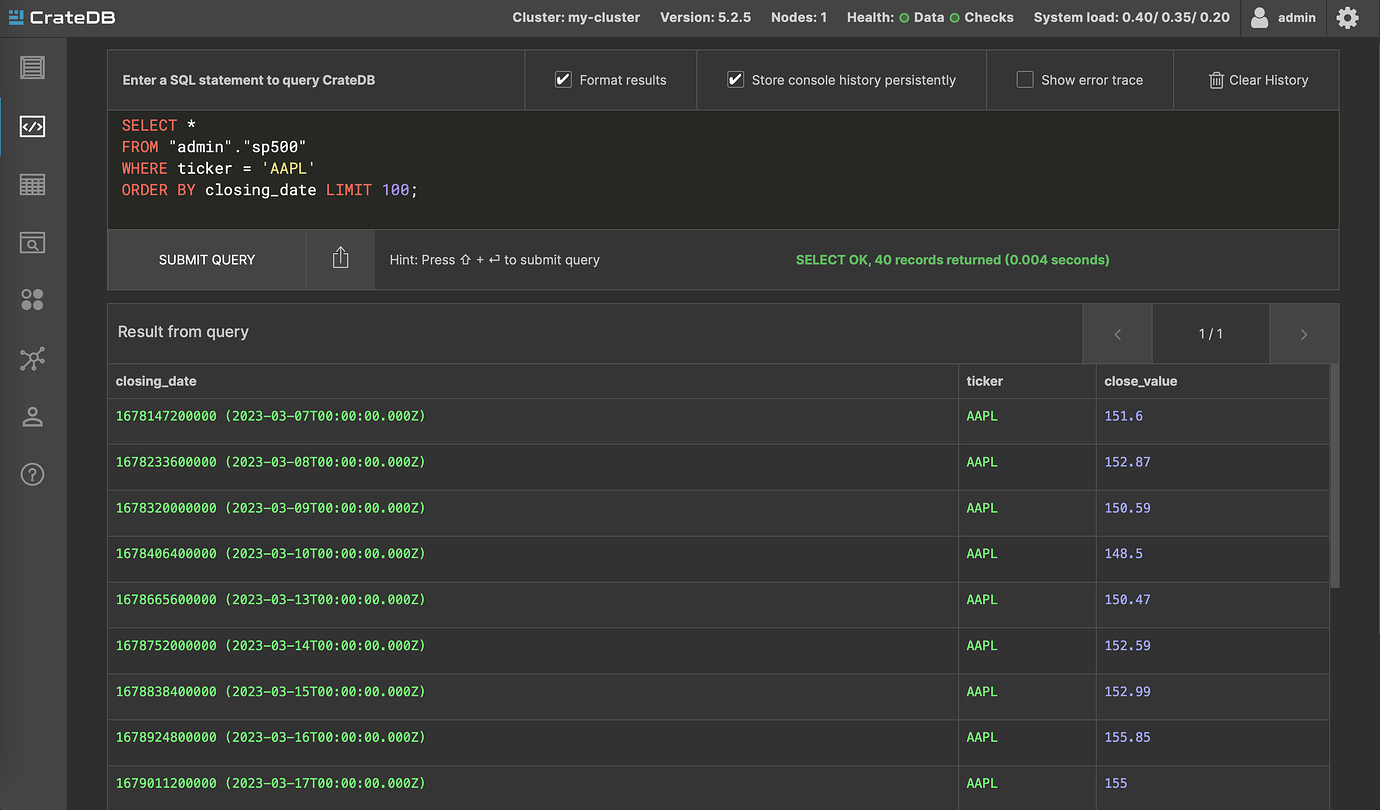
Now I can run this script whenever I want to update my database with new data!
Wrap up
In this post, I introduced a method to download financial data from Yahoo Finance using Python and pandas and showed how to insert this data in CrateDB.
I profited from CrateDB’s high efficiency in rapidly inserting a large amount of data into my database and presented a method to get the most recent input date from CrateDB. That way, I can efficiently keep my records in CrateDB up to date!


