March 23rd was a very special day: the second edition of CrateDB Community Day took place, and we couldn't be happier with the great talks we had in this 1-hour event!
The event started with a very warm welcome by our already familiar and favorite co-hosts: Rafaela Sant'ana, Developer Advocate Intern and Marija Selaković, Developer Advocate at CrateDB 👩🏻💻👩🏽💻
After welcoming our attendees from all around the globe, it was time to kick off four great talks. Keep reading and take a look at the highlights of each one 👇

Analyzing data in real-time with Metabase and CrateDB
Luis Paolini, Success Engineer at Metabase shared the details on how Metabase and CrateDB can work together by doing a quick demo and presentation. We loved his enthusiasm 👏

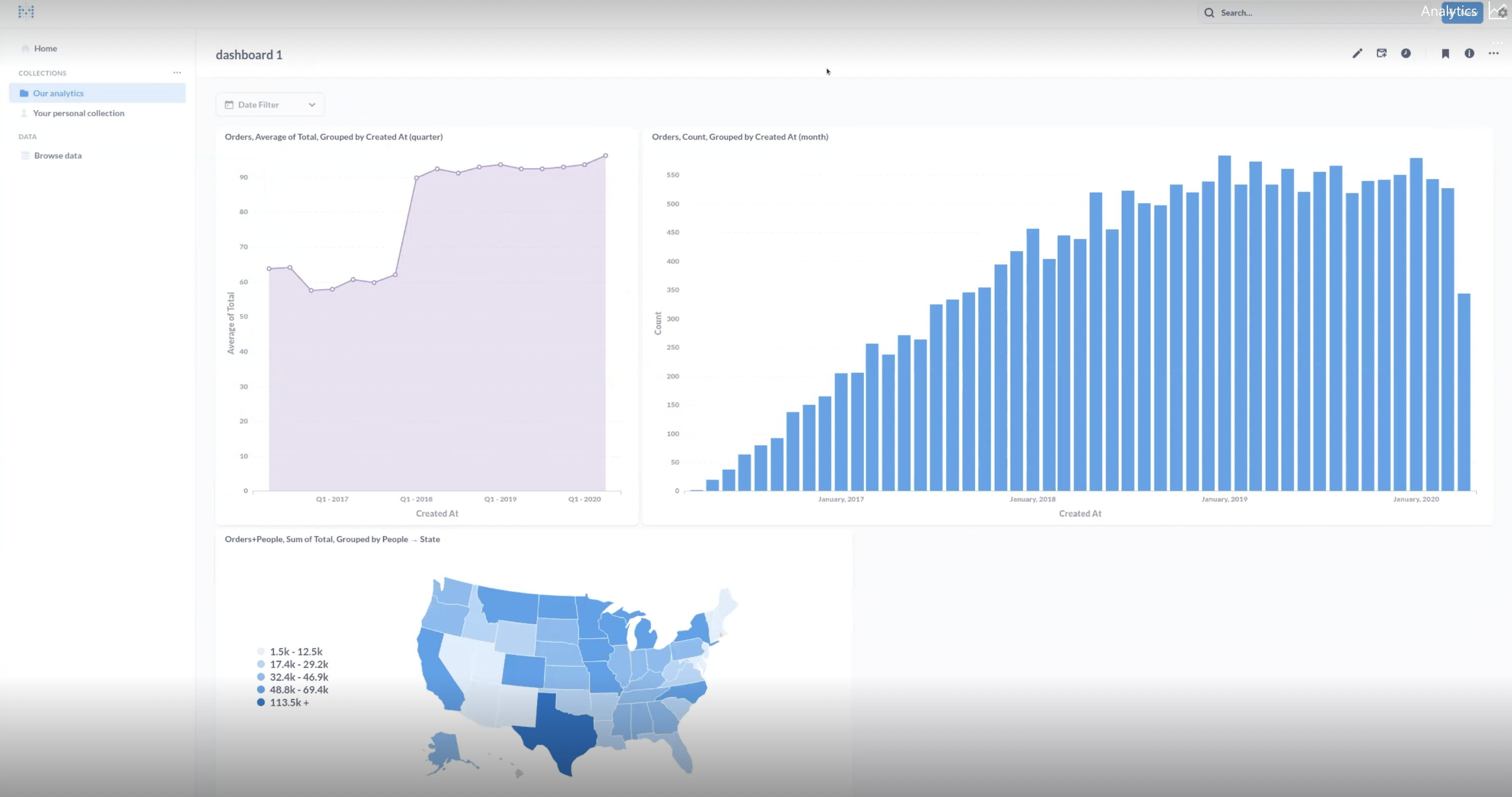
According to Luis Paolini, Metabase really allows you to do self-service analytics. It's a powerful analytics tool that makes it easy for everyone to dig into data on their own without needing to know SQL, giving power to non-technical users.
This demo showed us how to use CrateDB and Metabase to get insights from various data types. As Luis Paolini shared, this can be run by a team of 10 people or 1,000, showing how flexible it is for users.
"You can go from zero to dashboard in 5 minutes." - Luis Paolini
You can watch the full demo here and learn how to get metadata from CrateDB to Metabase and analyze data in real-time in just a few minutes. Know more about the demo with Luis Paolini on his community post here.
How Kooky gets insights from large amounts of data with CrateDB
Dmytro Boguslavskyy, CTO & Co-Founder, and Kostyantyn Lyuty, Head of Engineering at Kooky, shared their use case with CrateDB, how it helped them analyze and gain insights from large amounts of data and how seamlessly it fits into Kooky's toolchain 💡
Dmytro shared that Kooky is a very heavy hardware and software-oriented solution. We were so happy to hear Kooky is really trying to make a positive environmental impact with their solution:
"Today's packaging is one of the biggest waste producers and Kooky is working on tracing and operating reusable food packaging in a circular lifecycle, with multiple object components in real-time connected to each other." - Dmytro Boguslavskyy
According to Dmytro, this can bring some challenges, especially if Kooky's goal is to do that in real-time. When consumers bring packages back, they need to get their deposit instantly. This creates complexity and this was a situation that they had to deal with.
"We had a specific challenge that we needed to tackle, mostly it was about cross-DB queries that have extremely low performance." - Dmytro Boguslavskyy
CrateDB came in handy with the loyalty system Kooky wanted to run for their consumers. Every time they brought a coffee cup, Kooky wanted them to get benefits and loyalty points, but they needed several pieces of information. Kooky needed to pull all of this data when the consumer returned the package. This is where CrateDB became part of the solution.
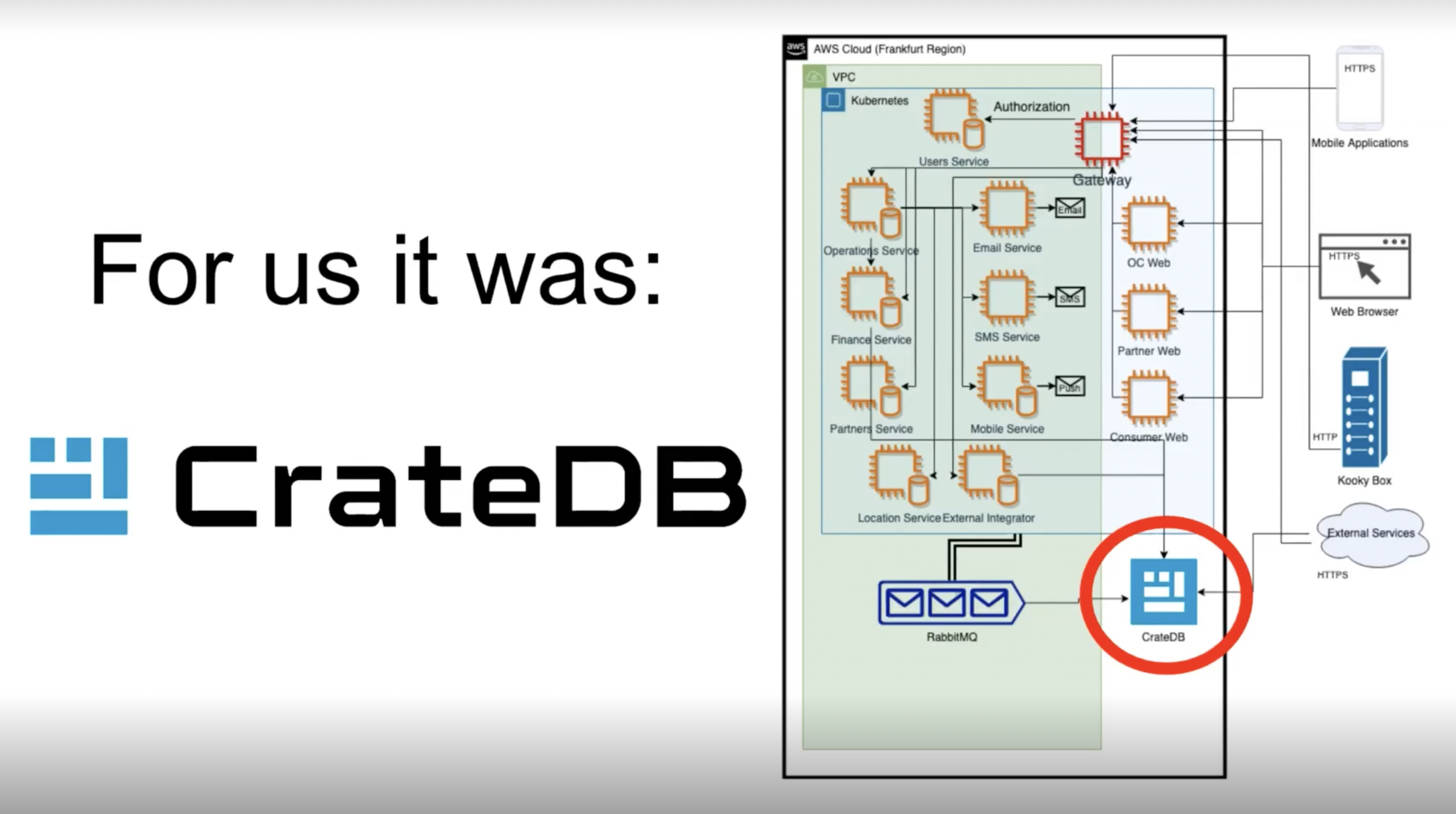
Kostyantyn shared that integrating CrateDB into their system was quite easy because of CrateDB’s PostgreSQL compatibility and high scalability.
The sequence was focused on spatial data, so it was dependable where the consumer picked up the cup and where they brought it back so the benefits the consumer receives depend heavily on all of this information. On the currency, this was difficult to figure out.
"With CrateDB it was extremely easy to have a single place that we could query through our entire system within milliseconds at any moment in time, and this was impossible before." - Dmytro Boguslavskyy

Know more about the technical side of this use case with Kostyantyn, where he explains how they integrated CrateDB. Watch the complete talk here.
An introduction to Apache Flink and Flink SQL
Timo Walther, Principal Software Engineer at Apache Flink shared with us a very insightful introduction to Apache Flink and Flink SQL.
According to Timo, if you want to do real-time processing, you need 4 building blocks, which he explains in detail 👇

"If we want to built in Apache Flinck a pipeline, actually you can design a pipeline like you would draw a dataflow on a whiteboard...what Flink does for you are all the heavy lifting and the background." - Timo Walther
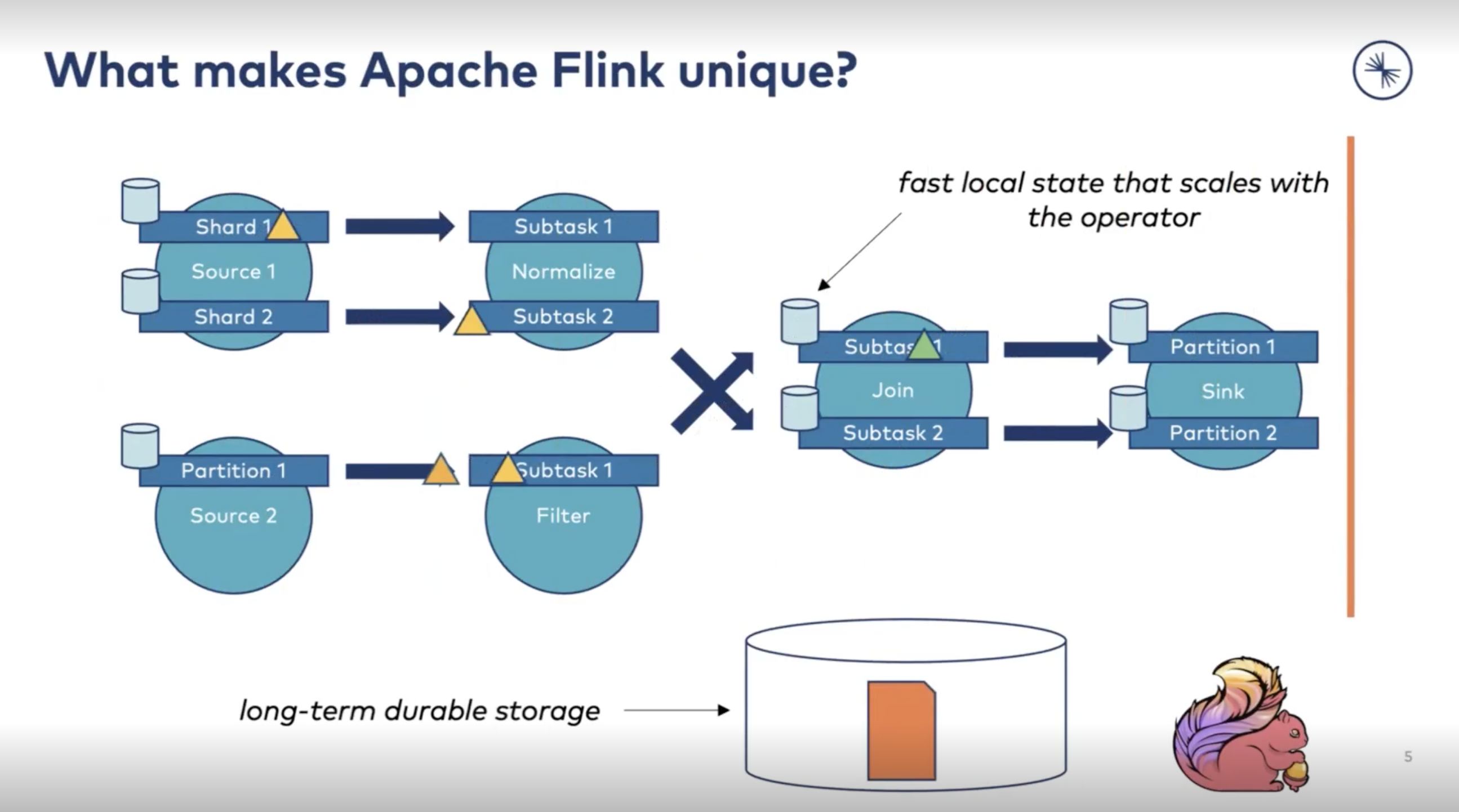
Timo shares that the use cases are very diverse when asked for what we can use Apache Flink. We can connect different messaging systems, file systems, and database key/value stores for multiple purposes. For data integrations, it can serve as a data hub between systems and much more like event-driven applications, and it's very flexible.
As it is open-source software, it's difficult to say for what Apache Flink is used. However, they have a strong community and several ways to connect. For example, their slack channel and others allow getting more insights into this. Some of the use cases include real-time data processing services, streaming feature platforms, internal cloud data infrastructure, and more.
Timo gives us more details about API Stack, Data Stream API, how to work with streams in Flink SQL and a practical example of stream-table duality. To listen to the complete details on all of these topics, watch the complete talk here 👈

Live demo of Apache Flink with CrateDB as source or sink
What better way to conclude this edition of CrateDB Community Day focused on integrations than with a live demo? 🙌
CrateDB Senior Software Engineer, Marios Trivyzas, shows us how to integrate Apache Flink with CrateDB and how to use CrateDB as a source or sink for an example use case.

Watch the complete event and check the questions our attendees asked 💭
See you at the next event! 👋


