In this article on automating recurrent CrateDB queries with Apache Airflow, we will present a second strategy for implementing a data retention policy.
Previously, we shared the Data Retention Delete DAG, which dropped old partitions after a certain period of time. In that article, we introduce the complementary strategy of a hot/cold storage approach.
What is a hot/cold storage strategy?
A hot/cold storage strategy is often motivated by a tradeoff between performance and cost-effectiveness. In a database such as CrateDB, more recent data tends to have a higher significance for analytical queries. Well-performing disks (hot storage) play a key role on the infrastructure side to support performance requirements but can come at a high cost. As data ages and gets less business-critical for near-real-time analysis, transitioning it to slower/cheaper disks (cold storage) helps to improve the cost-performance ratio.
In a CrateDB cluster, nodes can have different hardware specifications. Hence, a cluster can consist of a combination of hot and cold storage nodes, each with respective disks. By assigning corresponding attributes to nodes, CrateDB can be made aware of such node types and consider if when allocating partitions.
CrateDB setup
To create a multi-node setup, we make use of Docker Compose to spin up three nodes – two hot nodes, and one cold node. For the scope of this article, we will not actually use different hardware specifications for disks, but each disk is represented as a separate Docker volume.
The designation of a node type is done by passing the -Cnode.attr.storage parameter to each node with the value hot or cold. The resulting docker-compose.yml file with two hot nodes and one cold node is as follows:
The cluster is started via docker-compose up. For more details, please see the above-linked documentation.
Once the cluster is up and running, we create our partitioned time-series table. By specifying "routing.allocation.require.storage" = 'hot' in the WITH clause, we configure new partitions to be placed on a hot node.
To validate the allocation of shards we insert a sample row:
The INSERT statement will implicitly trigger the creation of a new partition consisting of six shards. Since we configured cratedb01 and cratedb02 as hot nodes, we expect shards to be allocated only on those two nodes, and not on cratedb03 (which is a cold node). The allocation can be validated by navigating to the “Shards” section in the Admin UI:
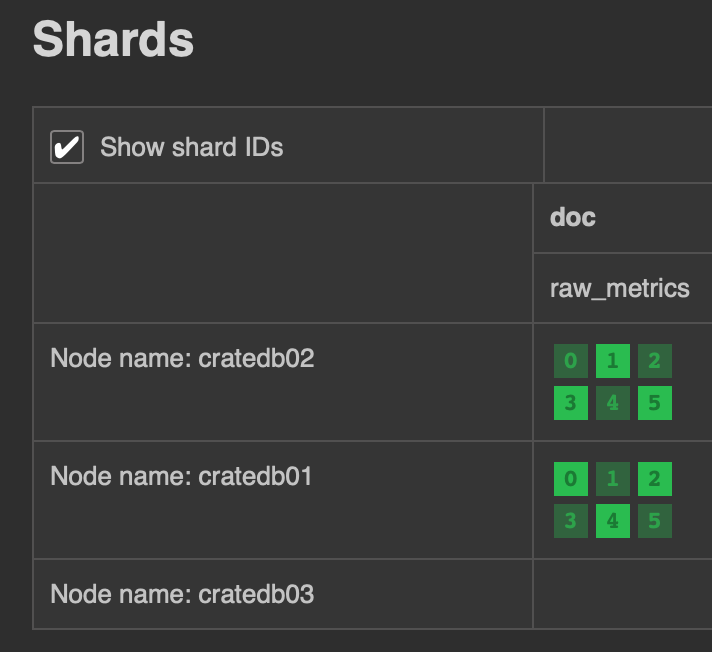
As expected, primary shards, as well as replicas, are evenly distributed between the first two nodes, while no shards are stored on the third node.
Next, we will create a table storing the retention policy used to transition partitions from hot to cold nodes:
The schema is an extension of what was introduced in the first article on the Data Retention Delete DAG. The strategy column allows switching between the previously introduced dropping of partitions delete) and the now added reallocation (reallocate). For ourraw_metrics table, we add a policy of transitioning from hot to cold nodes after 60 days:
To remember which partitions have already been reallocated, we can make use of the attributescolumn in sys.nodes which reflects the hot/cold storage attribute we configured in the Docker Compose setup.
Airflow setup
We assume that a basic Astronomer/Airflow setup is already in place, as described in our first post of this series. The general idea behind the hot/cold DAG implementation is similar to the one introduced in the initial data retention post. Let’s quickly go through the three steps of the algorithm:
get_policies: A query ondoc.retention_policiesandinformation_schema.table_partitionsidentifies partitions affected by a retention policy.map_policy: A helper method transforming the output ofget_policiesinto a Python dict data structure for easier handling.reallocate_partitions: Executes an SQL statement for each mapped policy:ALTER TABLE <table> PARTITION (<partition key> = <partition value>) SET ("routing.allocation.require.storage" = 'cold');
The CrateDB cluster will then automatically initiate the relocation of the affected partition to a node that fulfills the requirement (cratedb03in our case).
The full implementation is available as data_retention_reallocate_dag.py on GitHub.
To validate our implementation, we trigger the DAG once manually via the Airflow UI at http://localhost:8081. Once executed, log messages of the reallocate_partitions task confirm the reallocation was triggered for the partition with the sample data set up earlier:
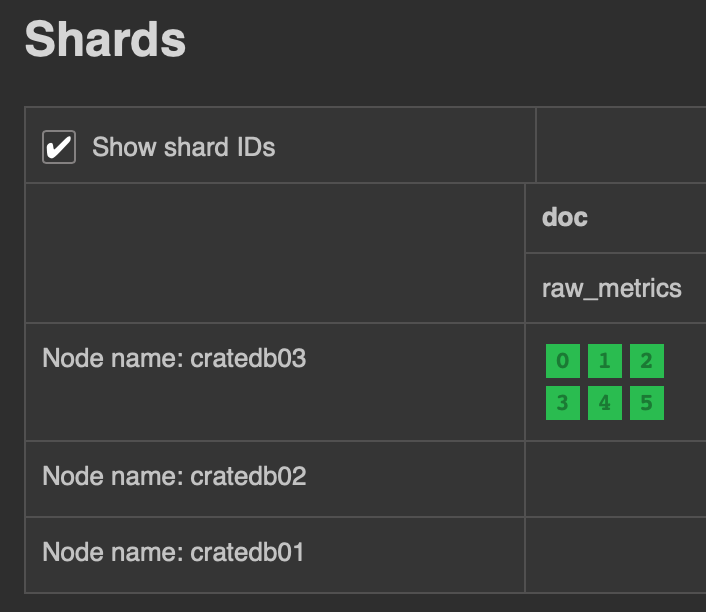
Revisiting the “Shards” section in the CrateDB Admin UI confirms that all shards have been moved to cratedb03. Since the default replication setting is 0-1 and there is only one cold node in this setup, replicas have been discarded.
Combined hot/cold and deletion strategy
The presented hot/cold storage strategy also integrates seamlessly with the previously introduced Data Retention Delete DAG. Both strategies can be combined:
- Transition to cold nodes: Reallocates partitions from (expensive) hot nodes to (cheaper) cold nodes
- Deletion from cold nodes: After another retention period on cold nodes, permanently delete partitions
Both DAGs use the same control table for retention policies. In our example, we already added an entry for the reallocate strategy after 60 days. If we want to keep partitions on cold nodes for another 60 days and then discard them, we add an additional delete policy. Note that the retention periods are not additive, i.e. we need to specify the delete retention period as 120 days:
Summary
Building upon the previously discussed data retention policy implementation, we showed that reallocating partitions integrates seemingly and consists only of a single SQL statement.
CrateDB’s self-organization capabilities take care of all low-level operations and the actual moving of partitions. Furthermore, we showed that a multi-staged approach to data retention policies can be achieved by first reallocating and eventually deleting partitions permanently.


