Introduction
CrateDB is an open-source, distributed database solution that makes storage and analysis of massive amounts of data very efficient. One of the key properties of CrateDB is a high level of scalability, flexibility, and availability. In addition, CrateDB supports the PostgreSQL wire protocol which makes integration with many data engineering tools simple and easy.
Apache Airflow is an open-source tool for programmatically authoring, scheduling, and monitoring data pipelines. With over 9M downloads per month it is the de facto standard for expressing data flows as Python code. Airflow can orchestrate tasks in many data engineering tools, including databases like CrateDB. Astronomer is the commercial developer behind Airflow—we offer Astro, a cloud native Airflow experience, as well as free comprehensive educational resources on Airflow.
Checking data quality to ensure characteristics such as consistency, completeness, and validity is essential to get actionable insights from your data. Which properties of the data are relevant to check depends on your use case, however automating data quality checks is key to have consistent control over the quality of information delivered to your end user.
Airflow features for dynamic data quality checks
In Airflow, data pipelines are expressed as DAGs (Directed Acyclic Graphs) with tasks as nodes and dependencies as edges. All tasks are defined in a Python file using Python classes called operators as building blocks. Some operators fulfill use cases as general as being able to turn any Python function into a task while others are highly specialized.
Among the many features of Apache Airflow, two are particularly useful for implementing dynamic data quality checks: dynamic task mapping and the SQL check operators.
Dynamic task mapping
Dynamic task mapping was introduced in Airflow 2.3 and allows the user to dynamically create an arbitrary number of parallel tasks based on an input parameter (the “map”).
To map a task, the parameters to the operator defining the task have to be passed through one of two functions:
- partial(): Contains any parameters that remain constant across all mapped tasks.
- expand(): Contains the parameters that will be mapped over within a Python dictionary or list.
The code snippet below shows how the task my_mapped_task is defined using the PythonOperator. The operator uses the custom Python function add_numbers() to add together mapped sets of numbers.
my_mapped_task = PythonOperator.partial(
task_id="my_mapped_task",
python_callable=add_numbers
).expand(op_args=[[19,23],[42,7],[8,99]])
Three sets of numbers were provided which resulted in the task my_mapped_task having 3 mapped instances, shown in the Airflow UI as a number in brackets. From the UI, each of the mapped instances can be accessed individually and will show the returned sum of one of the additions in their logs.
![my_mapped_task [3]](https://lh3.googleusercontent.com/4NrHE5RXPvsU6DtSewWIeB3vdYtAO6mUFkyqxQ8wdqSAflbt1FzSJ9uko4yDg5DBjy8Cuo0WcLXGIIkksWmJJWKrzkieMOdJpi-J_bhtmrwgLkhjZi9UnGX67YHizSn4fUkDm43jVGb2gJHh)
With dynamic task mapping it is possible to map over a parameter that changes with every task run, resulting in dynamic generation of the right number of tasks every time. You can even use the results of an upstream task as an input to a mapped task by passing information between tasks using the Airflow XComs feature.
In the example below we will use dynamic task mapping to map over a changing number of files in an S3 bucket to transfer their contents into a CrateDB table.
SQL Check operators
Airflow offers a variety of options for running checks on a database like CrateDB from any point within the data pipeline. One of the tools that can be used are SQL check operators, which are a family of operators designed to run data quality checks on any database that can be queried using SQL.
For our use case we were able to leverage the functionality of both the SQLTableCheckOperator and the SQLColumnCheckOperator. You can access these operators in your own Airflow instance by installing the Common SQL provider package.
pip install apache-airflow-providers-common-sql
SQLColumnCheckOperator
The SQLColumnCheckOperator is a Python class containing the logic to create an Airflow task which runs data quality checks against a table in a database.
You will need to provide the operator with the following parameters:
- task_id: The name of your task in the Airflow metadata database.
- conn_id: The name of the Airflow connection to CrateDB (see the example below).
- table: The table that is being queried in your CrateDB database.
- column_mapping: The data quality checks defined using a dictionary.
The code snippet below shows a SQLColumnCheckOperator which will run two checks on the MY_DATE column in MY_TABLE to ensure that each entry is greater than or equal to the 1st of January 2022, and to ensure that there are no null values.
column_checks = SQLColumnCheckOperator(
task_id="column_checks",
conn_id="cratedb_connection",
table="MY_TABLE",
column_mapping={
"MY_DATE": {
"min": {"geq_to": datetime.date(2022, 1, 1)},
"null_check": {"equal_to": 0}
}
}
)The SQLColumnCheckOperator has the ability to run a whole list of data quality checks on several columns of a table in a database. Since the task will only be marked as successful if all checks pass, you can make downstream actions in your data pipeline directly dependent on the quality of your data!
SQLTableCheckOperator
Similar to the SQLColumnCheckOperator, the SQLTableCheckOperator allows you to define checks involving several columns of a table in a dictionary provided to a parameter, this time called checks.
It is possible to have both checks on aggregate values like AVG() or SUM() and checks on a per-row basis.
This code snippet shows two checks on MY_TABLE:
- Make sure there are at least 1000 rows
- Make sure that in every row the value in MY_COL_3 is the sum of the values in MY_COL_1 and MY_COL_2
table_checks = SQLTableCheckOperator(
task_id="table_checks",
conn_id="cratedb_connection",
table=" MY_TABLE ",
checks={
"row_count_check": {
"check_statement": "COUNT(*) > 1000"
},
"col_sum_check": {
"check_statement": MY_COL_1 + MY_COL_2 = MY_COL_3
}
}
)
Use case: smart home data
We can bring all of these features together to orchestrate data quality checks on smart home data. Our smart home contains sensors collecting information on total energy generation and consumption, as well as energy usage of different household appliances. Additionally, information on weather conditions is being collected. The data arrives periodically in a file system and we want to design a pipeline that runs once a day to ingest all new data into CrateDB, but only after ensuring that the new batch of data satisfies our data quality needs.
In this article we will highlight the key steps we took to implement a DAG running dynamic data quality checks for our use case. The complete project can be found in our public GitHub repository.
Creating two tables in CrateDB
Before we start writing the Airflow DAG we need to create two tables for the data we will ingest. One table will temporarily hold the data to run the data quality checks on, and the other table will permanently store all data that has passed its checks.
Let’s take a closer look at the schema:
CREATE TABLE IF NOT EXISTS "iot"."smart_home_data" (
"time" INTEGER,
"use_kW" DOUBLE PRECISION,
"gen_kW" DOUBLE PRECISION,
"house_overall" DOUBLE PRECISION,
"dishwasher" DOUBLE PRECISION,
"home_office" DOUBLE PRECISION,
"fridge" DOUBLE PRECISION,
"wine_cellar" DOUBLE PRECISION,
"garage_door" DOUBLE PRECISION,
"kitchen" DOUBLE PRECISION,
"barn" DOUBLE PRECISION,
"well" DOUBLE PRECISION,
"microwave" DOUBLE PRECISION,
"living_room" DOUBLE PRECISION,
"temperature" DOUBLE PRECISION,
"humidity" DOUBLE PRECISION
)
The time column contains a timestamp of the sensor reading, while use_kW, and gen_kW columns contain total used and generated energy, respectively. Most of the other columns show how much electricity is consumed by individual devices and rooms. Finally, the data is augmented with information about the weather, namely temperature, and humidity.
Planning the Airflow DAG
Now that we understand the dataset and have created our tables, let’s take a closer look at the orchestration pipeline. Our DAG consists of several steps and is illustrated in Figure 1:
- Import of the files containing the data from a local filesystem to an “ingest” directory in a S3 bucket.
- Transfer the data from each file in the S3 bucket to a temporary table in CrateDB using dynamic task mapping.
- Run data quality checks on the temporary table in CrateDB.
- If all checks run successfully, move the data to a permanent table in CrateDB.
- Clean the temporary table.
- Move all processed files from the original S3 directory to a “processed” directory for permanent storage.
- Delete all files from the original directory using dynamic task mapping.
- In case of any task has failed, we report the issue by sending a message to a Slack channel using the on_failure_callback feature.
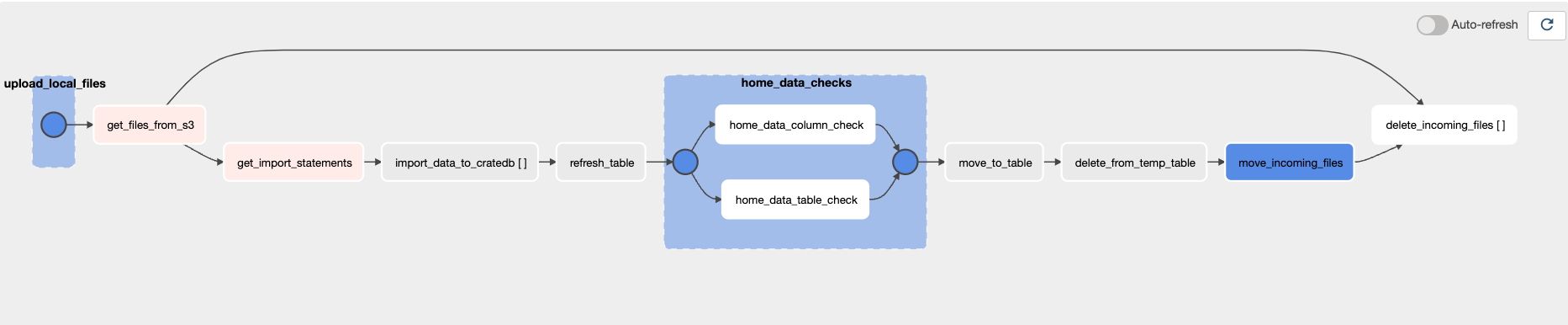
Figure 1. Overview of the DAG
This DAG will need two Airflow connections, one to the S3 bucket and one to CrateDB. We will show how to create the latter in the next section. For further instructions on how to set up other connections please refer to the “Managing your Connections in Airflow” guide linked in the resources.
Establishing a CrateDB connection
There are two commonly used ways to set up an Airflow connection to CrateDB: via the Airflow UI or by using an environment variable. In this article, we will specify the connection as an environment variable which goes in a .env file:
AIRFLOW_CONN_CRATEDB_CONNECTION=postgresql://<user>:<password>@<host>/doc?sslmode=disableThe connection is established via the PostgreSQL wire protocol and requires your username, password, and CrateDB host address. In case a TLS connection is required, set sslmode=required. Make sure to use percent-encoding for special characters.
Queries on CrateDB can be run from the Airflow DAG using the PostgresOperator. To connect the PostgresOperator to CrateDB and run any SQL query, you only need to specify three operator parameters:
- postgres_conn_id: Set this parameter to cratedb_connection which is what we called the connection in the environment variable above.
- sql: Enter a valid SQL query.
- task_id: Provide a unique name for each task in a DAG.
The PostgresOperator uses the first two parameters to run the provided SQL query on the CrateDB database which was defined in the cratedb_connection as one task in our DAG.
Importing data from S3 to CrateDB
To move our data from the S3 bucket to CrateDB we will utilize a CrateDB COPY FROM statement. This command imports the content of a CSV or JSON file from a URI to a table. Currently, CrateDB supports two URI schemes: file and s3.
In this article, we use the s3 scheme to access the data in the Amazon S3 bucket.
The syntax for the COPY FROM statement follows the structure:
COPY iot.smart_home_data FROM 's3://[{access_key}:{secret_key}@]<bucket>/<path>'The official CrateDB documentation on COPY FROM offers more information on syntax and available options for this statement.
To execute the COPY FROM statement we need one task using the PostgresOperator with CrateDB connection credentials per file in the S3 bucket. However we don’t have upfront information about the number of files that will need to be imported at every DAG run. This is where dynamic task mapping comes into play.
First, we need to get a list of the files currently in the “ingest” directory of the S3 bucket using the list_keys() method of the S3Hook. Next, we iterate over the filenames to create one COPY FROM statement for each:
@task
def get_import_statements(bucket, prefix_value):
s3_hook = S3Hook()
file_paths = s3_hook.list_keys(bucket_name=bucket, prefix=prefix_value)
statements = []
for path in file_paths:
sql = f""" COPY {TEMP_TABLE} FROM 's3://{ACCESS_KEY_ID}:
{SECRET_ACCESS_KEY}@{S3_BUCKET}/{path}' WITH (format='csv');"""
statements.append(sql)
return statementsNow we can use dynamic task mapping to create a dynamically changing number of tasks to execute each COPY FROM statement in CrateDB:
import_stmt = get_import_statements(S3_BUCKET, prefix)
import_data = PostgresOperator.partial(
task_id="import_data_to_cratedb",
postgres_conn_id="cratedb_connection"
).expand(sql=import_stmt)Implementing data quality checks
To ensure the correctness and consistency of the smart home data we want to run the following data quality checks for each batch of smart home data before adding it to our permanent table:
- time: All values in this column should be unique.
- time, use_kW, and get_kW: Values in these columns should be NOT NULL.
- temperature and humidity: Values in these columns should be in a certain range, Between 0 and 1 for humidity and between -20°C and 99°C for temperature.
- Every import should have more than 100,000 rows.
- Electricity usage on the house level should always be greater or equal to the sum of all usage information available from different devices and different rooms.
We define these data quality checks using the template based dictionary format shown previously and run them with the SQLTableCheckOperator and the SQLColumnCheckOperator.
The full implementation of all data quality checks can be found on our public GitHub repository. Here, we want to show how we created the tasks running the two last checks on our list using the SQLTableCheckOperator.
To define the table_checks task we need to provide the SQLTableCheckOperator with a task_id, as well as the conn_id of the CrateDB database and the table we are querying. The data quality checks are provided to the checks parameter of the operator.
In the code snippet below we define two checks that we name row_count_check and total_usage_checks (the names can be chosen freely). Each of the checks has an associated check_statement that defines the condition that the current batch of data has to fulfill for the check to pass. The home_data_table_check task will only be marked as successful if the data passes both checks.
table_checks = SQLTableCheckOperator(
task_id="home_data_table_check",
conn_id="cratedb_connection",
table=TEMP_TABLE,
checks={
"row_count_check": {
"check_statement": "COUNT(*) > 100_000"
},
"total_usage_check": {
"check_statement": "dishwasher + home_office + "
+ "fridge + wine_cellar + kitchen + "
+ "garage_door + microwave + barn + "
+ " well + living_room <= house_overall"
}
}
)Next steps
We hope that this article gave you a primer on running data quality checks in CrateDB using Apache Airflow and made you curious to learn more. Our DAG structure is one of many possible approaches, thus we encourage you to try out the features we highlighted and to adapt them to your requirements. There are many data engineering challenges you can solve using Apache Airflow with CrateDB.
Here are some helpful resources to continue your journey:
- Dynamic tasks in Airflow: A guide providing in-depth instructions on dynamic task mapping.
- Airflow data quality checks with SQL operators: A guide diving deeper into the SQL Check operator family and explaining their use cases.
- Data quality and Airflow: A guide on how to design data quality checks and what tools are available to implement them from within an Airflow pipeline.
- Managing your Connections in Apache Airflow: A guide containing explanations on how to create connections to external tools in Airflow.
- CrateDB documentation
- Tamara's talk on CrateDB Community Day
Watch Tamara's Talk at CrateDB Community Day
If you have additional questions about building dynamic orchestration pipelines with Airflow and CrateDB please get in touch with the Airflow and CrateDB communities. If you are interested in running your data pipelines on Astro, a cloud native managed Airflow experience, you can contact Astronomer directly to discuss your data orchestration needs.


