You can easily use Apache Camel to receive data from one endpoint and send it to CrateDB.
Learn how Digital Factory Vorarlberg GmbH uses Apache Camel and CrateDB for collecting, processing, and analyzing the power consumption data of multiple machines.
What is Apache Camel
Apache Camel is an open-source integration framework designed to make integrating systems simple and easy. It allows end users to integrate various systems using the same API, and exchange, route, and transform data using different protocols. It supports numerous backend systems, allows the introduction of custom protocols, and provides powerful routing and filter capabilities.
Getting started with CrateDB
One of the easiest ways to start an instance of CrateDB is to use CrateDB's official docker image:
docker run --publish=4200:4200 --publish=5432:5432 --pull=always --env CRATE_HEAP_SIZE=1g crate
After you spin the docker image you can access the Admin UI in your browser at http://localhost:4200/.
To run a fully managed cluster, deploy a new cluster on CrateDB Cloud. By creating a new CrateDB Cloud account you get entitled to a $200 free credit to spend on cluster deployment, scaling, and other operations as you see fit.
Digital Factory Vorarlberg GmbH Use Case
This article is based on a real setup in the lab of the Digital Factory Vorarlberg GmbH.
The Digital Factory Vorarlberg GmbH operates a model factory for testing, exploring, and developing tools and methods for digitized production. The model factory uses a pool of different machines, such as robots, a milling machine, and a transport system, which reflects the heterogeneous nature of real-world manufacturing environments.

A major task for digitized manufacturing is the analysis of data generated during the process and applying the findings of this analysis to the process. For this purpose, measurement boxes collect usage data of the various machines in the model factory, which is stored in CrateDB. This data is used for such analysis and to create a machine learning model, the energy twin. The energy twin can be used to predict the power consumption of tasks to be executed and help optimize the production process. As did the model factory, the infrastructure for collecting this data grew over time. Therefore, we reimplemented the data collection process using Apache Camel.
The following diagram gives an overview of our data pipeline.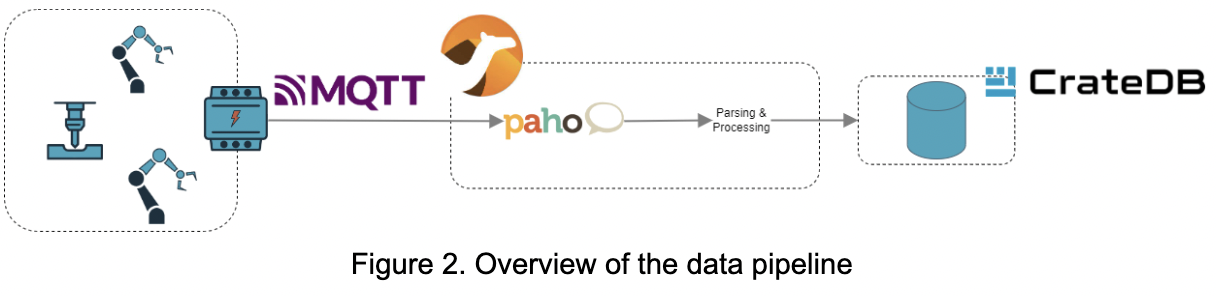
Data schema
A message produced by a measurement box looks as follows:{ "ID" : "MB1", "TS" : 133111640608230000, "V_RMS" : [ 227.76926042248544, 227.8165708750111, 227.77828257360093], "I_RMS" : [ 0.6525507233651466, 0.6798045633696993, 0.6746791587100572], "P" : [ 115.30679291657198, 115.5200239036747, 24.963654985975175 ], "S_ap" : [ 148.63099564903735, 154.8707444920691, 153.67726005917876 ], "PF" : [ 0.7757923736771981, 0.7459124980805556, 0.16244208789486522 ], "f" : [ 50.02683759072172, 50.02678422023895, 50.02686304547146 ], "W" : [ 1.4119106884809995, 1.4217046606550117, 0.4821352931017049 ]}
The ID identifies the measurement box that published the message and the timestamp gives the date and time on which the data was sampled. All other entries are lists of values with each index corresponding to one socket of the box.
- V_RMS: Root mean square value of voltage
- I_RMS: Root mean square value of current
- P: Active power over a 40ms interval
- S_ap: Apparent Power over a 40ms interval
- PF: Power Factor (P/S) over an 40ms interval
- f: Frequency
- W: Cumulative energy
Setting up a new Apache Camel project
Apache Camel provides Maven archetypes to set up new projects. For the example described here, we used the following, which creates a project that runs Camel as a standalone:
GroupId: org.apache.camel.archetypeArtifactId: camel-archetype-mainVersion: 3.20.1
Camel offers a variety of components for creating routes. Since for our use case, the data is published using MQTT, a publish/subscribe messaging protocol, we need a component that can retrieve the published messages. We use the Eclipse Paho component. A component can be easily added to the project by adding it as a Maven dependency:
<dependency> <groupId>org.apache.camel</groupId> <artifactId>camel-paho</artifactId></dependency>
Each measurement box has dedicated MQTT topics with which they are communicating with other systems. Other systems can then operate on these messages or, as is the case in the integration setup described here, persist the data to be used in applications that require historical data.
Connecting to CrateDB
For connecting to CrateDB we use the JDBC component, which allows us to connect to and interact with SQL databases. Furthermore, we use the PostgreSQL driver for the connection to CrateDB and Apache DBCP for providing the actual data source. Camel provides integration with the Spring framework, nevertheless, we can define and register beans in a stand-alone setup as well. We use this to configure the database connection. For providing the data source DBCP is used. The method depicted below receives its parameters from a configuration file. We use the PostgreSQL driver and configure the data source as needed.
We define a data source as a bean and configure it using the application properties (see here for an example file). To do so, we add a method to the MyConfiguration class as illustrated below:
@BindToRegistrypublic BasicDataSource psqlSource(@PropertyInject("db.url") String url, @PropertyInject("db.user") String user, @PropertyInject("db.password", defaultValue = “”) String password, @PropertyInject("db.ssl", defaultValue = “false”) String ssl) { BasicDataSource source = new BasicDataSource(); source.setDriverClassName("org.postgresql.Driver"); source.setUrl( url); source.addConnectionProperty("user", user); source.addConnectionProperty("password", password); source.addConnectionProperty("ssl", ssl); return source;}
The annotation BindToRegistry binds the bean to the Apache Camel registry, by default with the name of the method, in this case, psqlSource. In the route definition, we reference the data source by this name.
As the driver, the PostgreSQL driver is used and the rest is configured according to the properties.
Writing data to CrateDB
Before writing data to CrateDB we need to preprocess it because the payload is received as an array of bytes. For processing messages in a route, we can implement the Processor interface provided by Camel. MQTT sends data as bytes. To better work with it we can unmarshal the data using, for example, Jackson. The process can then work on this unmarshalled object. The processing needed in the use case mainly involves converting the timestamp and converting the object into a format that can be processed by components used later in the Camel route.
When talking about the data published by the measurement boxes we already saw that P and PF are calculated over a 40ms interval. This is also the interval in which measurements are published. Therefore, 25 messages are published per second per measurement box. In total 4500 messages are to be processed by the integration pipeline per minute. Although this is a quite moderate number of messages per second, we can already improve the performance of the integration pipeline by not inserting each measurement separately but by inserting them in batches. The SQL component supports named parameters, as well as batch inserts. Our query looks like this:
INSERT INTO messbox (timestamp, vrms, irms, p, sap, pf, f, w, tool) VALUES(:#ts, :#vrms, :#irms, :#p, :#sap, :#pf, :#f, :#w, :#tool);
This query is located in a file called insert.sql and is located in the resource folder and the subfolder sql. Before we can use all this we have to (1) create a map from the unmarshalled object and (2) collect multiple messages to be inserted as one batch.
The first step, creating a map from the unmarshalled object is done by the processor implementation mentioned before. For collecting multiple messages we can add an aggregation step to our route. The aggregation step uses a list to collect the body of all incoming messages until a given number is reached. Such a route configuration could look similar to this:
.aggregate(AggregationStrategies .flexible() .accumulateInCollection(ArrayList.class) .pick(body())) .constant(true) .completionSize(10)
We can then use this list of maps to batch insert the data to CrateDB:
.to("sql:classpath:sql/insert.sql?dataSource=#psqlSource&batch=true")
The SQL file to use is referenced in the URI. The parameters define the data source created before and indicate to insert the data in batches.
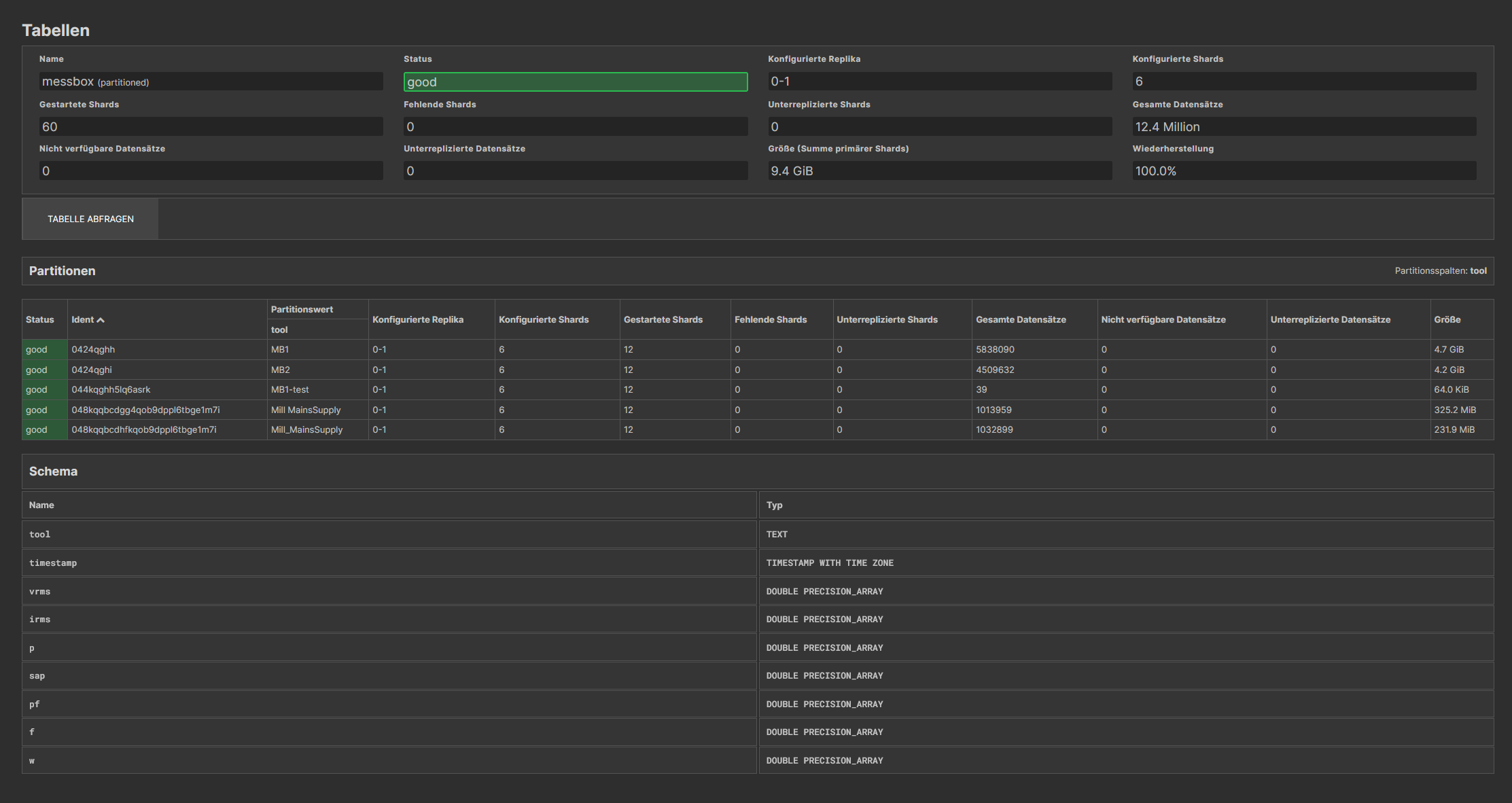 Figure 3: Data schema in CrateDB
Figure 3: Data schema in CrateDB
Next steps
In this article, we illustrated how Digital Factory Vorarlberg GmbH is using CrateDB with Apache Camel to collect, process, and analyze power consumption data from multiple machines. They also provided an implementation of an example data integration that is open-source and available in the Git repository. Use it to learn more about CrateDB and Apache Camel integration or as a starting point in implementing your own data integrations.
If you want to learn more about Apache Camel or CrateDB, feel free to join the discussions in the Apache Camel community and CrateDB community forum.
The CrateDB team thanks Digital Factory Vorarlberg GmbH Researcher Damian Drexel for collaborating with CrateDB's Customer Engineering team in creating this great article! ![]()


