Sharding and partitioning are very important concepts when it comes to system scaling.
When defining your strategy, you should account upfront for any future growth, given the significant burden of moving data and restructuring the tables.
In this article, we will give you a thorough understanding of how sharding and partitioning work in CrateDB. We will start by covering the basic definitions, discussing the principles behind shard distribution and replication in CrateDB, and how to avoid common bottlenecks.
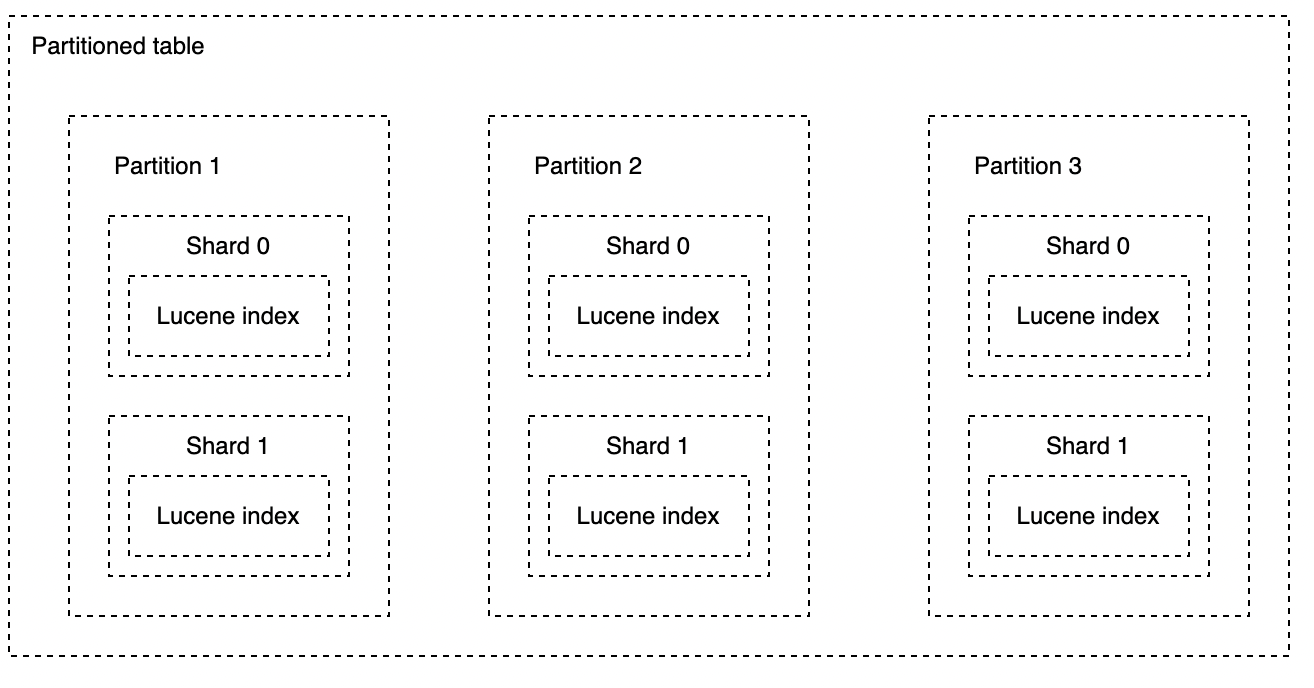
Partition, shard, and Lucene index
A table in CrateDB is a collection of data. It consists of a specified number of columns and any number of rows. Every table must have a schema describing the table structure. Very often, the table is divided into independent, smaller parts based on a particular column. This “smaller part“ is called a partition.
The table becomes a partitioned table if, during the table creation, a partition column is defined. In this case, when a new record is inserted, a new partition is created if the partition for the same column value doesn’t exist yet. Partitioning is done for easier maintenance of large tables and improving the performance of particular SQL operations. However, a bad selection of a partition column can lead to too many partitions, which can slow the system's performance.
Now let’s take a look into the concept of shard. In CrateDB, the shard is a division of a table or a table partition based on a configurable number and stored on a node in the cluster. When a node is added or removed from the cluster or when the data distribution becomes unbalanced, CrateDB automatically redistributes the shards across the nodes in the cluster to ensure an even data distribution. If the number of shards is not defined during table creation, CrateDB will apply a sensible default value depending on the number of nodes.
Finally, each shard in CrateDB represents a Lucene index. A Lucene index is a collection of Lucene segments where each segment represents an inverted index, doc value, or k-d trees. Take a look at our previous article to get a better overview of the Lucene index and Lucene segments.
The diagram below illustrates the best connection between partitions, shards, and the Lucene index.
How the data is distributed
CrateDB uses row-based sharding to split data across multiple shards. This means that data is split based on the values in specific columns of the table and distributed across multiple nodes. The column that the data should be sharded on is called the routing column. When you insert, update, or delete a row, CrateDB will use the routing column value to determine which shard to access. The number of shards and the routing column can be specified in the CLUSTERED clause when creating a table:
CREATE TABLE product ( product_id INT PRIMARY KEY, name TEXT, amount INT) CLUSTERED INTO 4 SHARDS;
In the above example, the product table is sharded into four shards. If the primary key is set, as illustrated, the routing column can be ignored, as CrateDB uses the primary key for routing by default. However, if the primary key or the routing column is not set, the internal document ID is used.
To distribute data across the cluster, CrateDB uses a hash-based approach based on the simple formula:
shard number = hash(routing column) % total primary shards
As a result, all documents with the same value of CLUSTERED BY column will be stored in the same shard. With a hash function, CrateDB will try to distribute the data roughly equally, even if the original data values are not evenly distributed.
Shard replication
Shard replication in CrateDB is a feature that allows you to replicate data across multiple nodes in a cluster. This can be useful for increasing data availability, improving performance, and reducing the risk of data loss. You can configure the number of replicas for each shard with the number_of_replicas table setting:
CREATE TABLE product ( product_id INT PRIMARY KEY, name TEXT, amount INT) WITH (number_of_replicas = 1);
When there are multiple copies of the same shard, CrateDB will mark one copy as the primary shard and treat the rest as replica shards. When data is written to a shard, it is first written to the primary shard. The primary shard then replicates the data to one or more replica shards on other nodes in the cluster. This process is done in real-time, ensuring that data is always up-to-date across all replicas.
In the event of a node failure, CrateDB will automatically promote one of the replica shards to become the new primary shard. Having more shard replicas means a lower chance of permanent data loss and more throughput as queries will utilize the extra replica shards so that the primary shard is not congested with many requests. In terms of the cost you pay, you will have higher disk space utilization and inter-node network traffic which leads to increased latency of inserts and updates. Additionally, CrateDB supports automatic failover, where the system automatically detects a failed node and promotes a replica shard to take its place as the primary shard.
It is also possible to specify the number of replicas for a specific table by using ALTER TABLE command. For instance:
ALTER TABLE product SET (number_of_replicas = 2);
Note that changing the number of replicas after a table is created will cause the cluster to redistribute the shards and may take some time to complete (if you want only new partitions to be affected, use the ONLY keyword).
Automatic creation of new partitions
Tables in CrateDB are designed to be dynamic and expandable, allowing for the addition of new rows and columns as needed. This means that you can create a table with an unlimited number of rows. Every time when new data is inserted, CrateDB dynamically creates a new table partition based on the partition column as illustrated by the following example:
CREATE TABLE sales (
"name" STRING,
"ts" TIMESTAMP,
"month" TIMESTAMP GENERATED ALWAYS AS date_trunc('month', ts),
"value" DOUBLE PRECISION
) CLUSTERED INTO 3 SHARDS
PARTITIONED BY (month);

For every unique value in the month column, a new partition will be created. In our example, the table can have up to twelve partitions, one for each month in the year. If more columns are used for partitioning a new partition will be created for every unique combination of values. The partition column can also be a generated column: columns whose values are calculated based on other columns. For instance, if you have a column containing a timestamp value, you can partition the data by a column that extracts the day value from the timestamp.
The automatic creation of new partitions allows for horizontal scaling and enables the database to handle large amounts of data by distributing it across multiple partitions. Each partition’s shard is stored on a separate node in a CrateDB cluster, which helps to improve query performance and reduce the load on individual nodes.
How to avoid too many shards
- If the routing column is badly chosen, you can end up with too many shards in the cluster, affecting the overall stability and performance negatively. To find out how many shards your tables need, you need to consider the type of data you are processing, required queries, and hardware configuration. However, if you end up with too many shards, you will have to manually reduce the number of shards by merging and moving them to the same node, which is a time-consuming and tedious operation. To get an idea of how many shards your cluster needs, check out our recent tutorial.
The general rule for avoiding performance bottlenecks is to have as least as many shards for a table as there are CPUs in the cluster. This increases the chances that a query can be parallelized and distributed maximally. However, if most nodes have more shards per table than they have CPUs, you could actually see performance degradation. Each shard comes with a cost in terms of open files, RAM, and CPU cycles. Having too many small shards can negatively impact performance and scalability for a few reasons: - Increased overhead in terms of managing and maintaining your cluster.
- Reduced performance because it takes longer for CrateDB to gather the results, especially true for queries that need to join data from multiple shards
- Limited scalability because it becomes more difficult to scale your cluster if you have too many shards.
- Increased complexity as too many shards can make it more difficult to understand and troubleshoot your data distribution.
Finally, for performance reasons, consider one thousand shards per node the highest recommended configuration. Also, a single table should not have more than one thousand partitions. If you exceed these numbers, you will experience a failing cluster check.
Takeaway
Sharding and partitioning in CrateDB are two key concepts that help to improve the scalability and performance of your database. In this article, we explored the basic principles of sharding and partitioning in CrateDB, and how they can be used to improve performance and scalability in your database. If you have any questions or want to learn more about CrateDB, check out our documentation and join the CrateDB community.