This post was written by Harshil Agrawal and Marija Selakovic and was originally published on the n8n blog.
Database backup is a mechanism to protect and restore a database. Periodical creation of database backups is important to ensure access to essential and critical data when the original source of data is unavailable. Planning how to make and manage database backups requires to take into account several considerations:
- What data should be stored based on its priority?
- How often should the backup be made?
- What kind of storage will be used?
- What is the retention policy for stored data?
In this article, we will show you how to implement some aspects of automated management of backups in the CrateDB database with no-code workflows in n8n.
Table of contents
The use case
In CrateDB, backups are called snapshots. They represent the state of the table, database, or table partitions at the time when the snapshot was created. Snapshots support incremental backups which means that a snapshot of the same table created later only stores data that are not already backed up.
To create snapshots, you need to first create a repository that is used for storing, managing, and restoring snapshots. To learn more about the types of repositories supported by CrateDB, please check the official documentation.
For the purpose of this article, we will use the well-known Iris Dataset. The dataset consists of 50 samples from each of three species of Iris where each sample is described by four features: sepal width, sepal length, petal width, and petal length.
Though we won’t cover all aspects of backup management, we will illustrate how to implement some of the important use cases, such as:
- Automatic generation of table backups
- Automatic assessment of memory usages by newly created or updated backups
- Management of stale backups
Prerequisites
To follow along this tutorial, you will need the following tools:
- CrateDB: a distributed database management system that makes it simple to store and analyze massive amounts of data in real-time. It is open-source, SQL compatible, based on shared-nothing architecture, and designed for high scalability.
- n8n: a fair-code licensed tool that helps you automate tasks, sync data between various sources, and react to events using a visual workflow canvas. You can select from more than 300 nodes to build an automation workflow.
In the next paragraphs, we will explain how to install both tools and how to import the Iris dataset in CrateDB.
Install CrateDB
One of the easiest ways to start an instance of CrateDB on your local machine run the following command in your terminal:
bash -c "$(curl -L https://try.crate.io/)"
The command downloads CrateDB and runs it from the tarball. After the download finishes, the command should open the CrateDB Admin UI. If this does not happen, open http://localhost:4200/ in your browser.
The CrateDB Admin UI should show up as illustrated below:
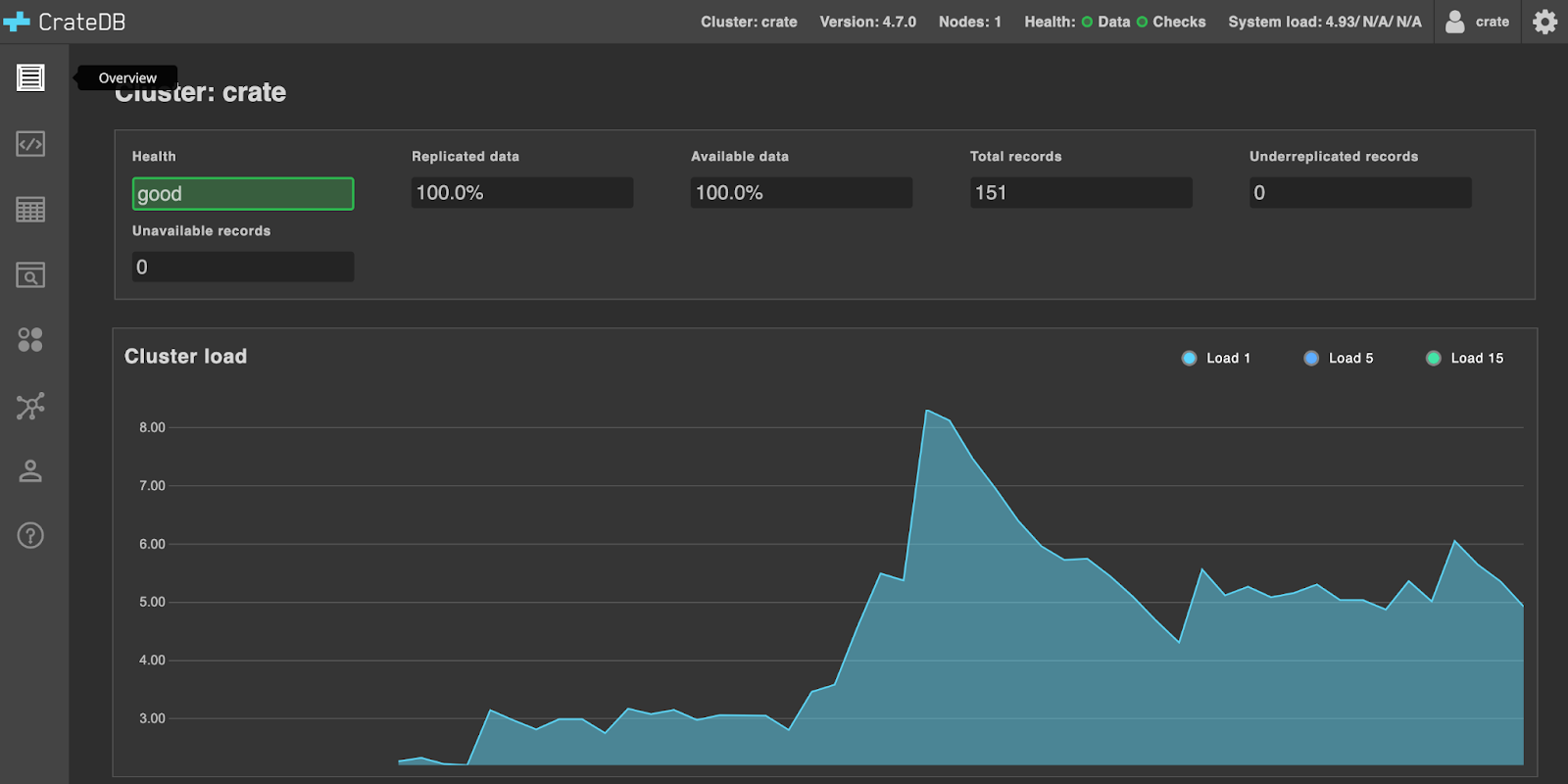
If you want to install CrateDB permanently check our collection of installation guides.
Import a sample dataset
To import the Iris dataset, you first need to create a new table in CrateDB and download data to your local machine. To create a table, run this query in Admin UI:
CREATE TABLE IF NOT EXISTS iris (
"Id" INT,
"SepalLengthCm" DOBULE,
"SepalWidthCm" DOUBLE,
"PetalLengthCm" DOUBLE,
"PetalWidthCm" DOUBLE,
"Species" TEXT
)
After creating the table, import the Iris dataset with the COPY TO statement using the following statement:
COPY doc.iris FROM ‘file:///path_to_file/Iris.csv’ RETURN SUMMARY;
Now you should find the iris table in the Tables section from the CrateDB Admin UI. By selecting the iris table you should be able to see the table schema as illustrated below:
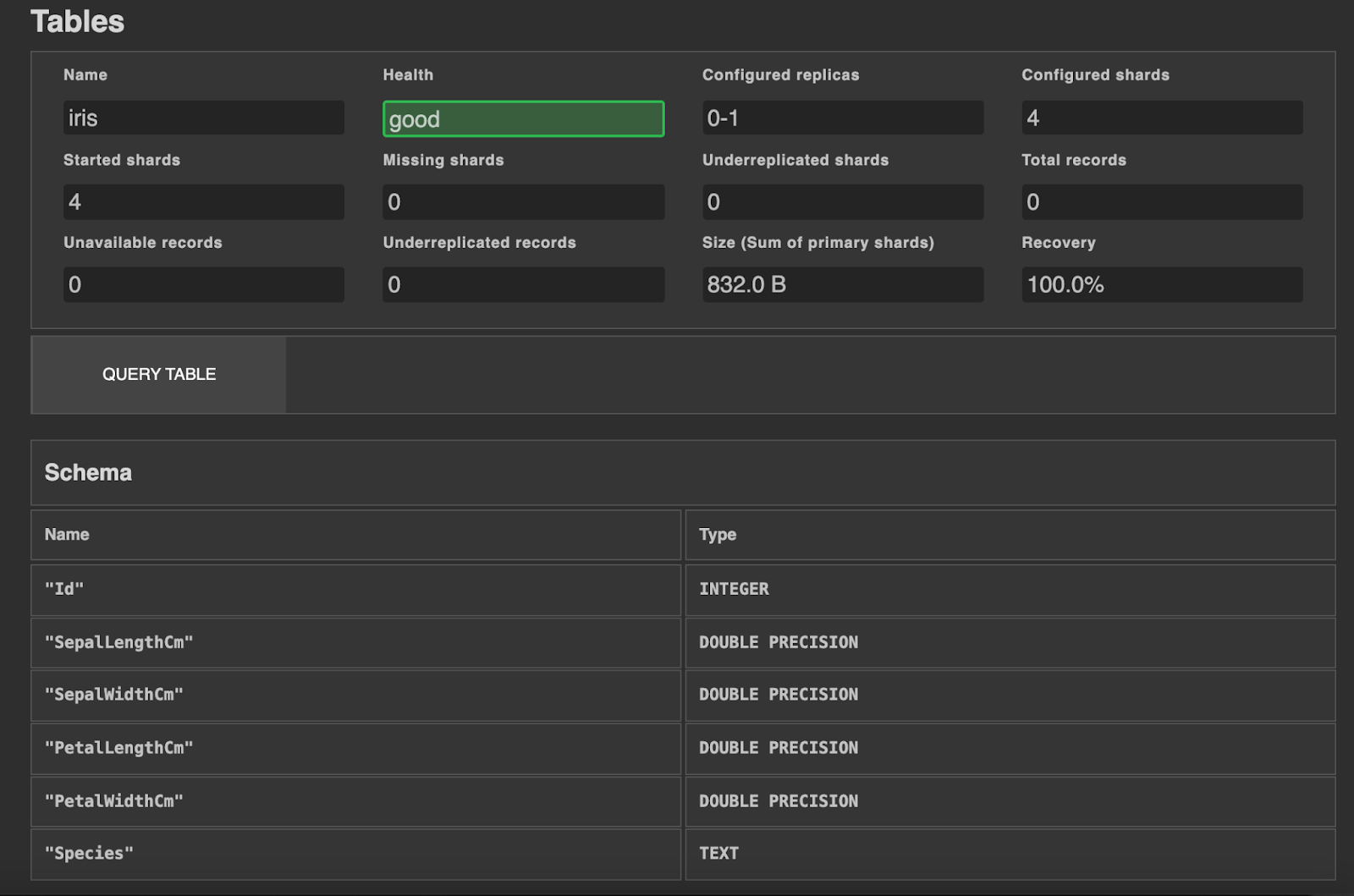 Iris table schema
Iris table schemaSet up n8n
To quickly get started with n8n, you can download and install the n8n Desktop app. You can also sign up for n8n.cloud to get a managed instance of n8n up and running. Alternatively, you can run n8n via npm or Docker.
Create a repository in CrateDB
The first step in backup management is the creation of a repository and snapshots of tables that need to be backed up regularly. For this article, we chose to create a repository on Amazon S3. CrateDB includes built-in support for other types of repository stores, such as local and remote filesystems, Hadoop Distributed File System (HDFS), and Azure.
Create a repository on Amazon S3 by running the following query from the Admin UI:
CREATE REPOSITORY temporary_backup TYPE s3 with (access_key =@access_key, secret_key = @secret_key, base_path=@base_path, bucket = @bucket_name);
Let’s take a closer look at the key parameters in this query:
- access_key and secret_key are security credentials for accessing AWS
- Bucket represents a name of s3 bucket where snapshot should be stored
- Base_path specifies the path in your s3 bucket. If the bucket does not yet exist, CrateDB will attempt to create a new bucket on Amazon S3.
Workflows for backup management
At this point, we assume that the repository has been created on the Amazon S3 instance. Now, we will build three workflows that automate three main tasks in backup creation and management:
- Generating snapshots and managing snapshots with high-memory usage
- Deleting “old” snapshots
- Triggering and reporting errors to team members with error workflows
In our workflows, we will use the following services:
- AWS S3 for searching and querying S3 buckets. To create a connection to S3 you need AWS credentials: access key and secret key.
- Slack for team communication. To send messages on the Slack channel you will need your Slack credentials. You can learn more about configuring Slack credentials in the documentation.
Now let’s see how to build each workflow.
Workflow 1 - Generate snapshots
The first workflow automates the generation of CrateDB snapshots. It creates a new snapshot every week, checks the size of the Amazon bucket used for snapshot storage, and if the size is higher than the configurable threshold, deletes the snapshot.
The final workflow consists of six nodes and looks like this:
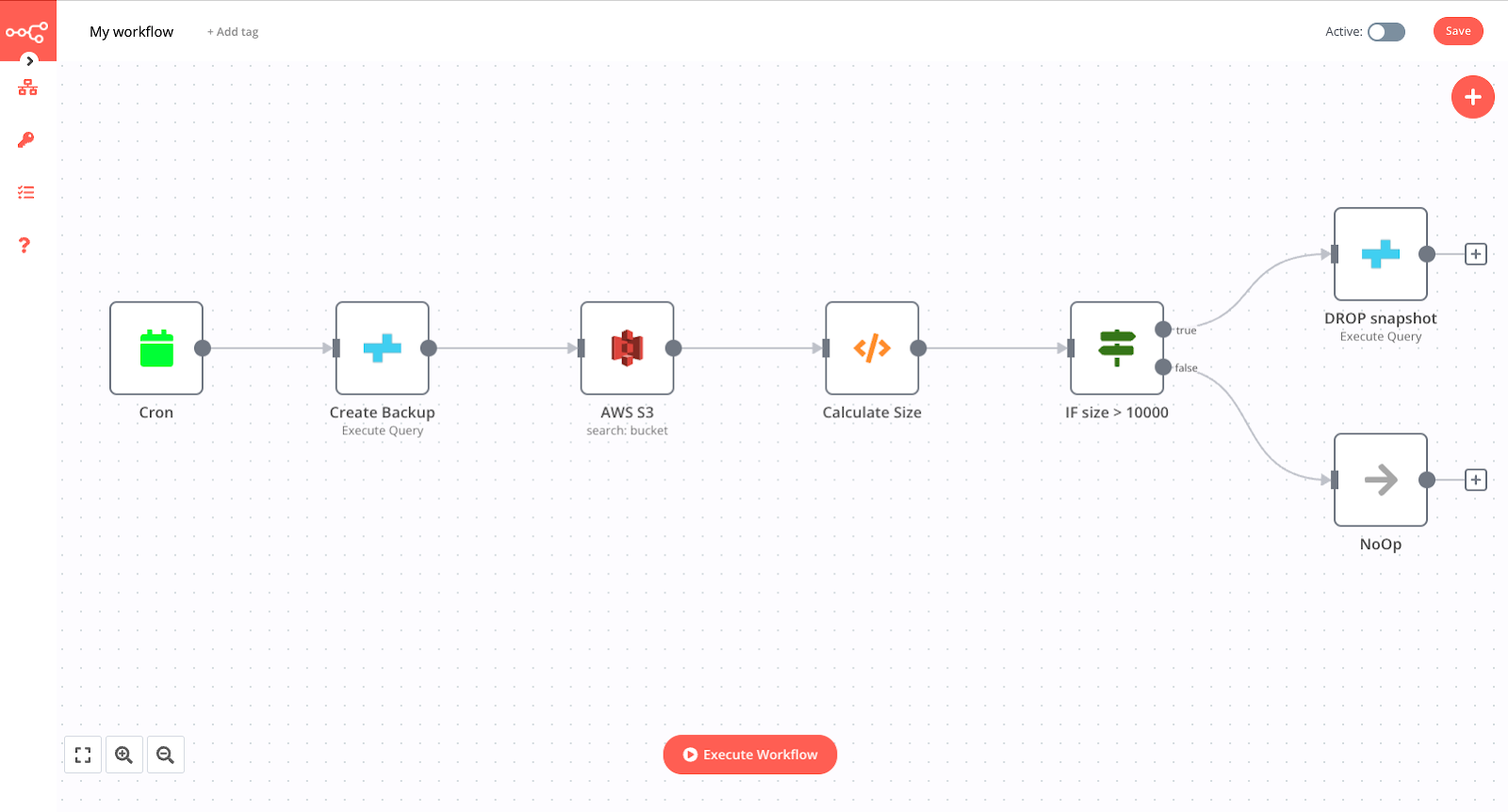
- Mode: Every Week
- Hour: 9
- Minute: 0
- Weekday: Monday
2. CrateDB node creates a new snapshot. To execute any query, you need to authorize the CrateDB node to access your local CrateDB instance. To authorize the node, select - Create New - from the Credential for CrateDB dropdown list. Use the following values:
- Host: localhost
- Database: doc
- User: crate
- SSL: disable
- Port: 5432
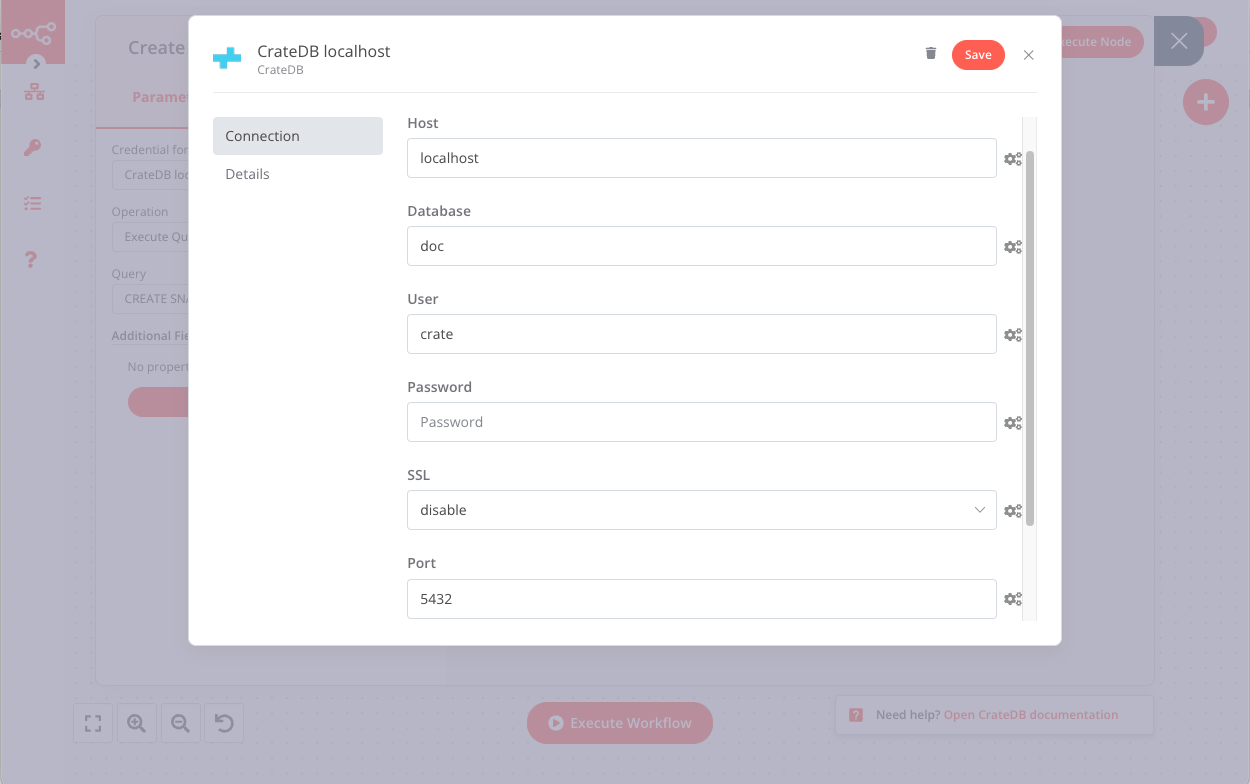
Then, use the following parameters inside the CrateDB node:
- Credential for CrateDB: your CrateDB credentials
- Operation: Execute Query
- Query > Add Expression: CREATE SNAPSHOT temporary_backup.iris_backup TABLE doc.iris;
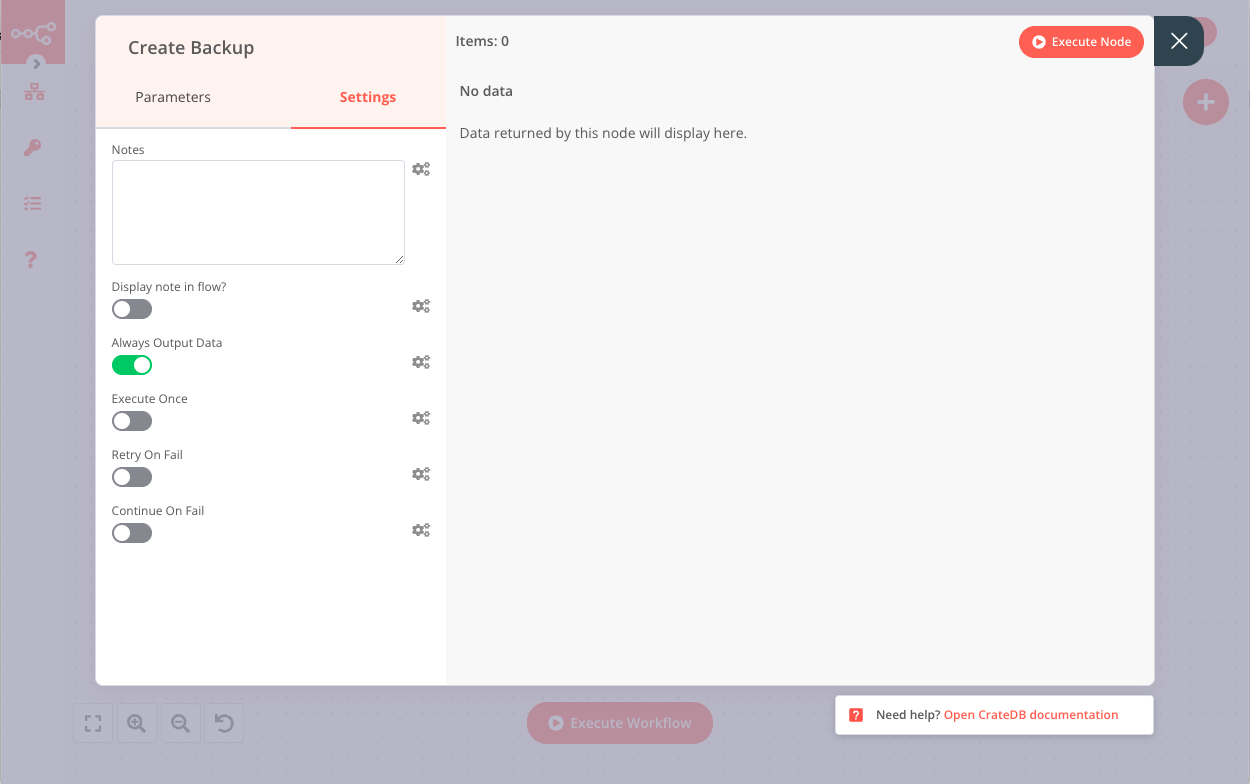
The statement creates a new snapshot called iris_backup inside the temporary_backup repository. If you execute the CrateDB node and the execution is successful, the node doesn’t return an output. However, output is necessary to allow the next nodes in the workflow to execute.
n8n allows you to continue the workflow even when a node returns no output. To configure this, click on the Settings tab of the node and enable the option Always Output Data.
3. AWS S3 queries the snapshot on the Amazon S3 bucket. In the AWS S3 node, configure the following parameters:
- Credential for AWS: your AWS S3 credentials
- Resource: Bucket
- Operation: Search
- Bucket Name: enter the name of the bucket you used when creating the Repository.
4. Function node calculates the size of the bucket in S3.
The AWS S3 node returns all the items in a bucket with their sizes. It doesn’t return the size of the bucket. To calculate the size of the bucket, you need to write a function that iterates over a list of items in the bucket and returns the total size.
In the Function node, write the following JavaScript function:
let size = 0;
for (item of items) {
size += parseInt(item.json.Size);
}
let newItems = [{json:{size}}];
return newItems;
5. IF node splits the workflow based on a comparison operation.
In our case, we want to delete a snapshot if its size is too large (and do nothing otherwise). In the IF node, configure the following parameters:
- Value 1 > Add Expression:
- Operation: Larger Equal
- Value 2: 1,000,000 (or any other threshold value)
6. CrateDB node deletes a snapshot if it exceeds the threshold. Use the credentials that you configured earlier, and enter the following query in the Execute Query field:
DROP SNAPSHOT temporary_backup.iris_backup;
This statement deletes iris_backup snapshot in temporary_backup repository and all files referenced by this snapshot.
You now have a workflow that automatically generates a backup, checks the size of the backup, and deletes them if they exceed the threshold value. In the next section, you will create a workflow that periodically deletes old snapshots.
Workflow 2 - Return and drop old snapshots
After some time certain snapshots become obsolete and in such a case, it is a good idea to delete them. These snapshots are not useful and just occupy space in the bucket. This workflow helps with periodically deleting old snapshots and freeing up the memory in your bucket.
The final workflow consists of four nodes and looks like this:
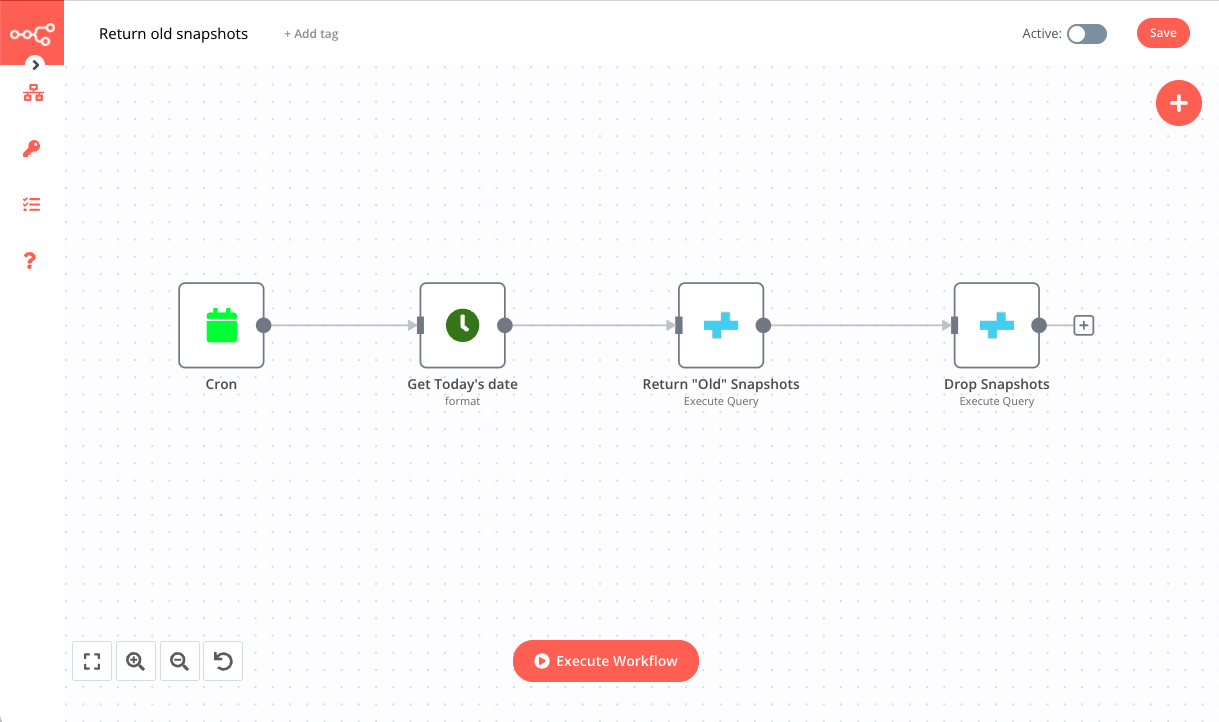
In this workflow we use the following nodes:
1. CRON node triggers the workflow at 5 AM every 15 days.- Mode: Custom
- Cron Expression: 0 5 */15 * *
2. Date & Time node returns the current date in the YYYY-MM-DD format. You will use this date in the next node to return older snapshots. Configure the node with the following parameters:
- Value: 0.0
- Property Name: current_date
- To Format: YYYY-MM-DD
- Options > From Format: X
3. CrateDB node executes the query that returns snapshots older than the current date.
- Credential for CrateDB: your CrateDB credentials
- Operation: Execute Query
- Query > Add Expression: SELECT * FROM sys.snapshots WHERE DATE_FORMAT('%Y-%m-%d',started) < '';
4. CrateDB node deletes each snapshot returned from the previous node.
- Credential for CrateDB: your CrateDB credentials
- Operation: Execute Query
- Query > Add Expression: DROP SNAPSHOT .
The statement deletes older snapshots from a repository and all files referenced by the snapshot.
After you activate the workflow, your workflow will automatically execute every 15 days, fetch old backups, and delete them.
In the next section, you will create a workflow that will help you monitor errors (if any) and alert your team.
Workflow 3 - Report workflow errors
The last piece of our automation workflow is the Error workflow. The goal of the error workflow is to notify the team if an error occurs during the workflow execution.
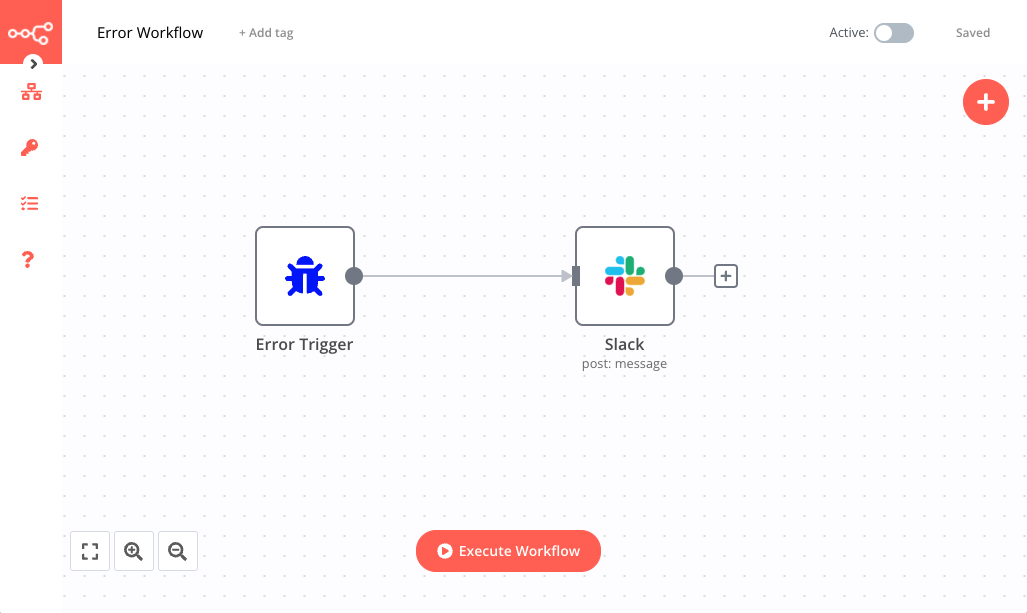
In the last workflow we use two nodes:
- Error Trigger node triggers the workflow when an error occurs in another workflow. You don’t need to configure any parameters in this node.
- Slack node allows the workflow to send a message on Slack.
Configure the following parameters:
- Credential for Slack API: your access token
- Authentication: Access Token
- Resource: Message
- Operation: Post
- Channel: channel where the message should be sent to
- Text: message to be sent
Now that you have created an error workflow, the next step is to configure the previous workflows to use this error workflow. Here’s how to do this:
- Open Workflow 1 (the workflow you want to monitor) in the Editor UI.
- In the left-side menu, click on Workflows > Settings.
- From the Error Workflow drop-down list, select Workflow 3 (the error workflow you created in this step).
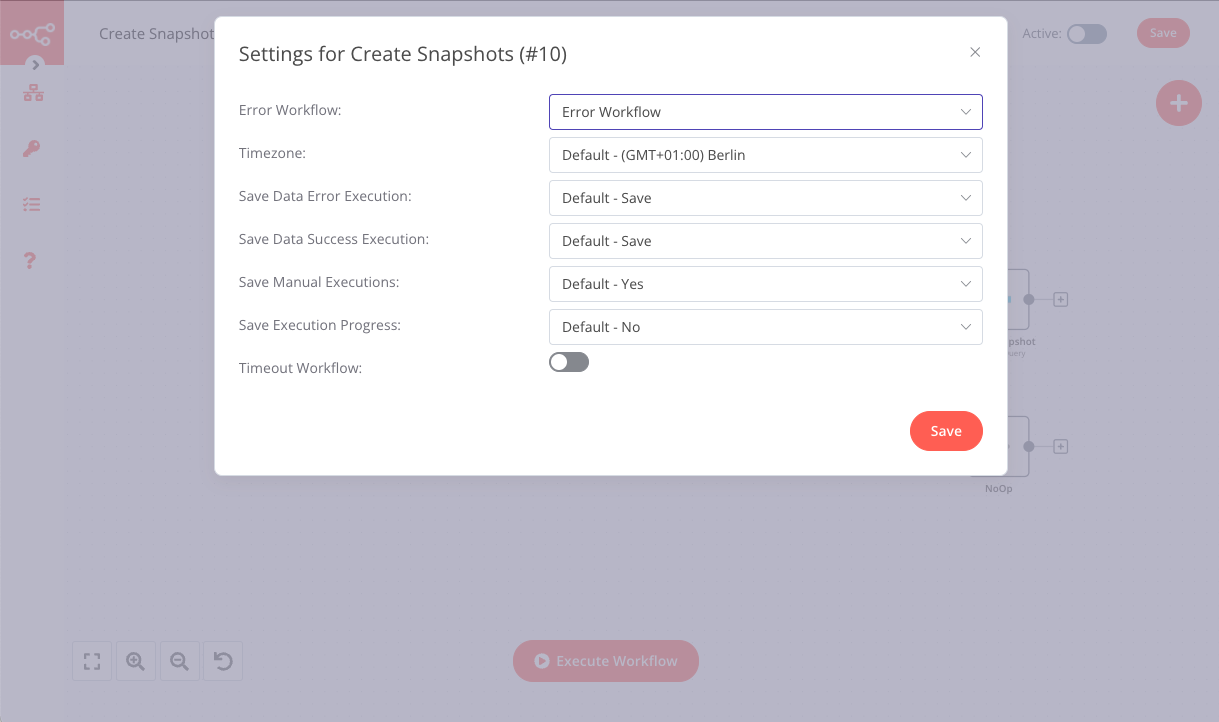
And that was it! Your automation process for backup management is now complete.
Start automating!
In this article, we showed you how to generate and manage CrateDB snapshots with low-code workflows in n8n. These workflows can be extended to cover other interesting use cases such as:
- Wait and alert if the snapshot creation or deletion doesn’t finish within a specified time frame
- Update snapshot every two weeks and delete only if the snapshot size exceeds the memory limit
- Combine memory size and longevity of a snapshot to decide if a snapshot should be deleted or not
As organizations manage more and more data, such automation helps achieve high availability and reliability of business-critical data.
If you want to learn more about low-code workflows in n8n or about CrateDB, feel free to join the discussions in the n8n community forum and CrateDB community forum.


