This blog post was originally published in March 2022 and has been updated to reflect recent developments.
One of CrateDB’s key strengths is scalability. With a truly distributed architecture, CrateDB serves high ingest loads while maintaining sub-second reading performance in many scenarios. In this article, we want to explore the process of scaling ingestion throughput. While scaling, one can meet a number of challenges - which is why we set ourselves the goal of scaling to an ingest throughput of 1,000,000 rows/s. As CrateDB indexes all columns by default, we understand ingestion as the process of inserting data from a client into CrateDB, as well as indexing.
But this should not become an artificial benchmark, purely optimized at showing off numbers. Instead, we went with a representative use case and will discuss the challenges we met to reach the 1,000,000 rows/s throughput.
Table of contents
- The strategy
- The ingest process
- The benchmark process
- The tools
- The infrastructure
- The results
- The conclusion
- The learnings
The strategy
The strategy to reach the throughput of 1,000,000 rows/s is relatively straightforward:- Come up with a non-trivial data model, that represents a realistic use case
- Start a single-node cluster and find the ingest parameter values that yield the best performance
- Add additional nodes one by one until reaching the target throughput
Let’s revisit at this point CrateDB’s architecture. In CrateDB, a table is broken down into shards, and shards are distributed equally across nodes. The nodes form a fully meshed network.
 Schematic representation of a 9-node CrateDB cluster
Schematic representation of a 9-node CrateDB cluster
The ingest process
With that cluster architecture in mind, let’s break down the processing of a single INSERT statement:
-
A client sends a batched INSERT statement to any of the nodes. We call the selected node the query handler node.
We will utilize a load balancer with a round-robin algorithm to ensure that the query-handling load is distributed equally across nodes. -
The query handler node parses the INSERT statement and assigns each row a unique ID (_id). Based on this ID and certain shard metadata, the query handler node assigns each row the corresponding target shard. From here, two scenarios can apply:
a. The target shard is located on the query handler node. Rows get added to the shard locally.
b. The target shard is located on a different node. Rows are serialized, transmitted over the network to the target node, deserialized, and finally written to the target shard.
For additional information on custom shard allocation, please see the CREATE TABLE documentation.
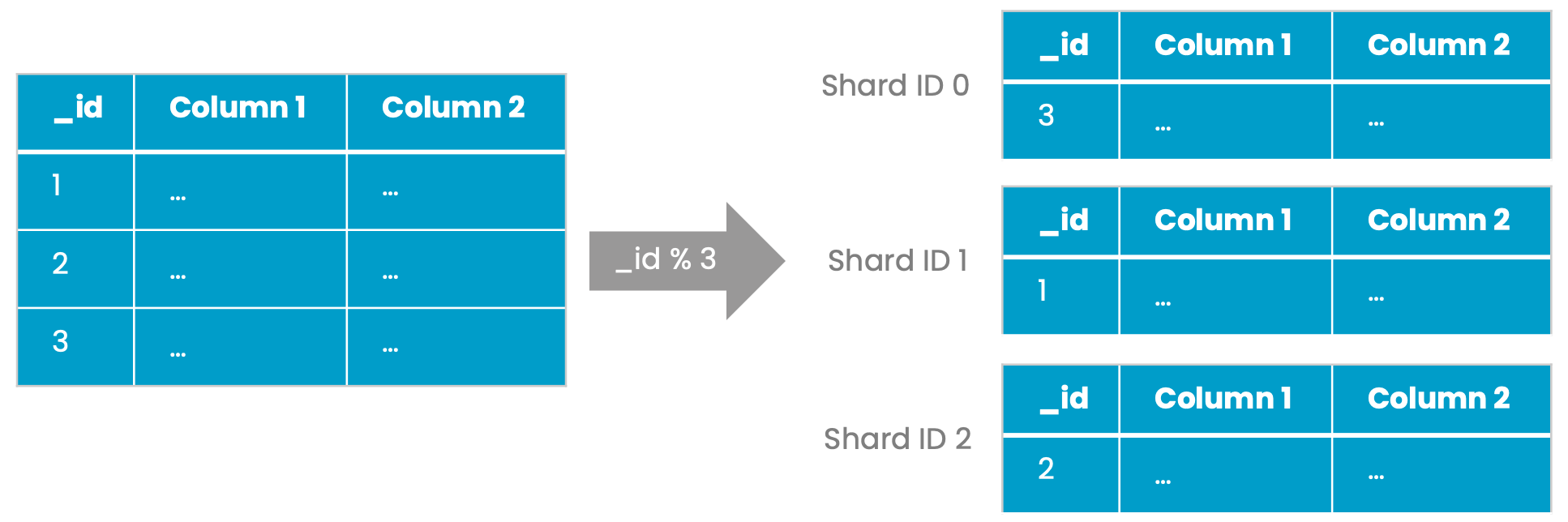 Distribution of rows to three shards based on the system-generated _id column
Distribution of rows to three shards based on the system-generated _id column
Scenario 2.a is best from a performance perspective, but as each node holds a roughly equal number of shards (approx. number of total shards / number of nodes), scenario 2.b will be the more frequent one. Therefore, we have to expect a certain overhead when scaling.
The benchmark process
Before running any benchmarks, the key question is: How to identify that a node/cluster has reached its optimal throughput?
A good first candidate to look at is CPU usage. CPU cycles are required for query handling (parsing, planning, executing queries) as well as for indexing data. CPU utilization of around 90% is a good first indicator that the cluster is well utilized. But looking at CPU usage alone can be misleading, as there is a fine line between well-utilizing and overloading the cluster. In CrateDB, each node has a number of thread pools for different operations, such as reading and writing data. A thread pool has a fixed number of threads that process operations. If no free thread is available, requests are rejected and operations get queued.
To reach the best possible throughput, we aim to keep threads fully utilized and have the queue of INSERT queries filled sufficiently. However, we also don't want to overload queues. The state of each node’s thread pools can be inspected via the system table sys.nodes. The below query sums up rejected write operations across all nodes. Note that this metric isn’t historized, so the number represents the total of rejected operations since a node’s last restart.
In our benchmarks, we will increase concurrent INSERT queries up to a maximum where no significant amount of rejections appear.
For a more permanent monitoring of rejected operations and several more metrics, take a look at CrateDB’s JMX monitoring as well as Monitoring an on-premises CrateDB cluster with Prometheus and Grafana.
The data model
The data model consists of a single table that stores CPU usage statistics from Unix-based operating systems. The data model was adopted from Timescale’s Timescale’s Time Series Benchmark Suite.
The tags column is a dynamic object which is provided as a JSON document during ingest. It describes the host on which the CPU metrics were captured. Furthermore, 10 numeric metrics are recorded, each modeled as top-level columns:
The number of shards will be determined later as part of the benchmarks. We will test both with and without replicas. All other table settings remain at their default values, which also means that all columns will get indexed.
The tools
To provision the infrastructure that our benchmark is running on, as well as to generate the INSERT statements, we make use of two tools:
-
crate-terraform: Terraform scripts to easily start CrateDB clusters in the cloud. It also allows configuring certain performance-critical properties, such as disk throughput. Going with Terraform guarantees that the setup will be easy to reproduce. We will run all infrastructure on the AWS cloud.
-
nodeIngestBench: The client tool that generates batched INSERT statements. Implemented in Node.js, it provides the needed high concurrency with a pool of workers that run as separate child processes.
The CrateDB version used was 5.4.0.
The infrastructure
For CrateDB nodes, we chose m6in.4xlarge instances. With 16 CPU cores and 64 GB RAM, we try to get a high base throughput for a single node and therefore keep the number of nodes low. m6in instances also provide good network performance for node-to-node communication. Each node has a separate disk containing CrateDB’s data directory which we provision with 400 MiB/s throughput and 5000 IOPS.
Additionally, we spin up another EC2 instance of the same type that will run the Node.js ingest tool.
To keep latency between the CrateDB cluster and the benchmark instance as low as possible, all of them are placed in the same subnet. We also configure the load balancer to be internal, so all traffic remains within the subnet.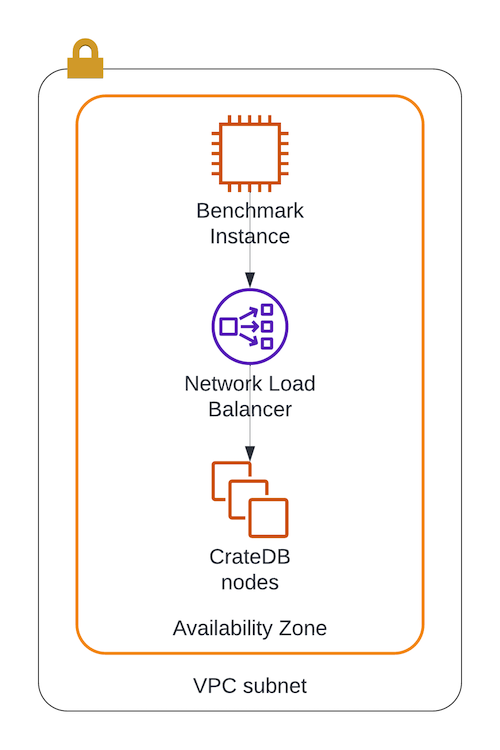 AWS setup used for benchmarks
AWS setup used for benchmarks
Below is the complete Terraform configuration. Please see crate-terraform/tree/main/aws for details on how to apply a Terraform configuration.
The results
Each benchmark run is represented by a corresponding call of our nodeIngestBench client tool with the following parameters:
Let’s break down the meaning of each parameter:
-
batch_size: The number of rows that are passed in a single INSERT statement. A relatively high value of 15.000 rows keeps the query handling overhead low.
-
shards: The number of primary shards the table will be split into. Each shard can be written independently, so we aim for a number that allows for enough concurrency. On adding a new node, we will increase the number of shards. Shards are automatically distributed equally across the nodes.
For a real-world table setup, please also consider our Sharding and Partitioning Guide for Time-Series Data. - replicas: The number of replica shards to make use of CrateDB’s replication for increased analytical query performance and high availability.
-
processes: The main node process will start this number of child processes (workers) that generate INSERT statements in parallel.
-
max_rows: The maximum number of rows that each child process will generate. It can be used to control the overall runtime of the tool. We will lower it slightly when scaling to keep the runtime at around five minutes.
-
concurrent_requests: The number of INSERT statements that each child process will run concurrently as asynchronous operations.
Single-node
We start simple with a single node deployment to determine the throughput baseline. As we have 16 CPU cores, we chose the same amount of shards.
Scaling out
We scale horizontally, by adding one additional node at a time. With each node, we also add another ingest client process to increase concurrency. As indicated before, node-to-node traffic also increases when scaling. To account for that overhead, we decrease the concurrent_requests parameter if needed (based on rejected operations).
Below are the full results without replicas, which also include all the required information to reproduce the benchmark run on your own:
| Nodes | Cluster size increase | Through-put (rows/s) | Throughput increase absolute (rows/s) | Throughput increase relative | Primary Shards | Processes | Concurrent requests |
|
1
|
293,147 |
16
|
1
|
16
|
|||
|
2
|
+ 100 %
|
493,723
|
+ 200,575
|
+ 68 %
|
24
|
2
|
12
|
|
3
|
+ 50 %
|
676,781
|
+ 183,058
|
+ 37 %
|
32
|
3
|
11
|
|
4
|
+ 33 %
|
856,460
|
+ 179,680
|
+ 27 %
|
40
|
4
|
10
|
|
5
|
+ 25 %
|
1,043,659
|
+ 187,198
|
+ 22 %
|
48
|
5
|
9
|
We reach the target throughput of 1,043,659 rows/s with a five-node cluster. As each row contains 10 metrics, it equals a throughput of 10,436,590 metrics/s.
The max_rows parameter was reduced from 95 million rows per child process to 71 million rows for the five-node cluster to remain within a runtime of five minutes.
Next, we repeat the measurements with one replica (--replicas 1). We start from two nodes, as replicas cannot be used on a single node. The number of primary shards is halved to keep the total number of shards equal.
| Nodes | Cluster size increase | Through-put (rows/s) | Throughput increase absolute (rows/s) | Throughput increase relative | Primary Shards | Processes | Concurrent requests |
|
2
|
286,341 |
12
|
2
|
12
|
|||
|
3
|
+ 50 %
|
403,630
|
+ 117,288
|
+ 41 %
|
16
|
3
|
11
|
|
4
|
+ 33 %
|
510,086
|
+ 106,456
|
+ 26 %
|
20
|
4
|
10
|
|
5
|
+ 25 %
|
629,568
|
+ 119,482
|
+ 23 %
|
24
|
5
|
9
|
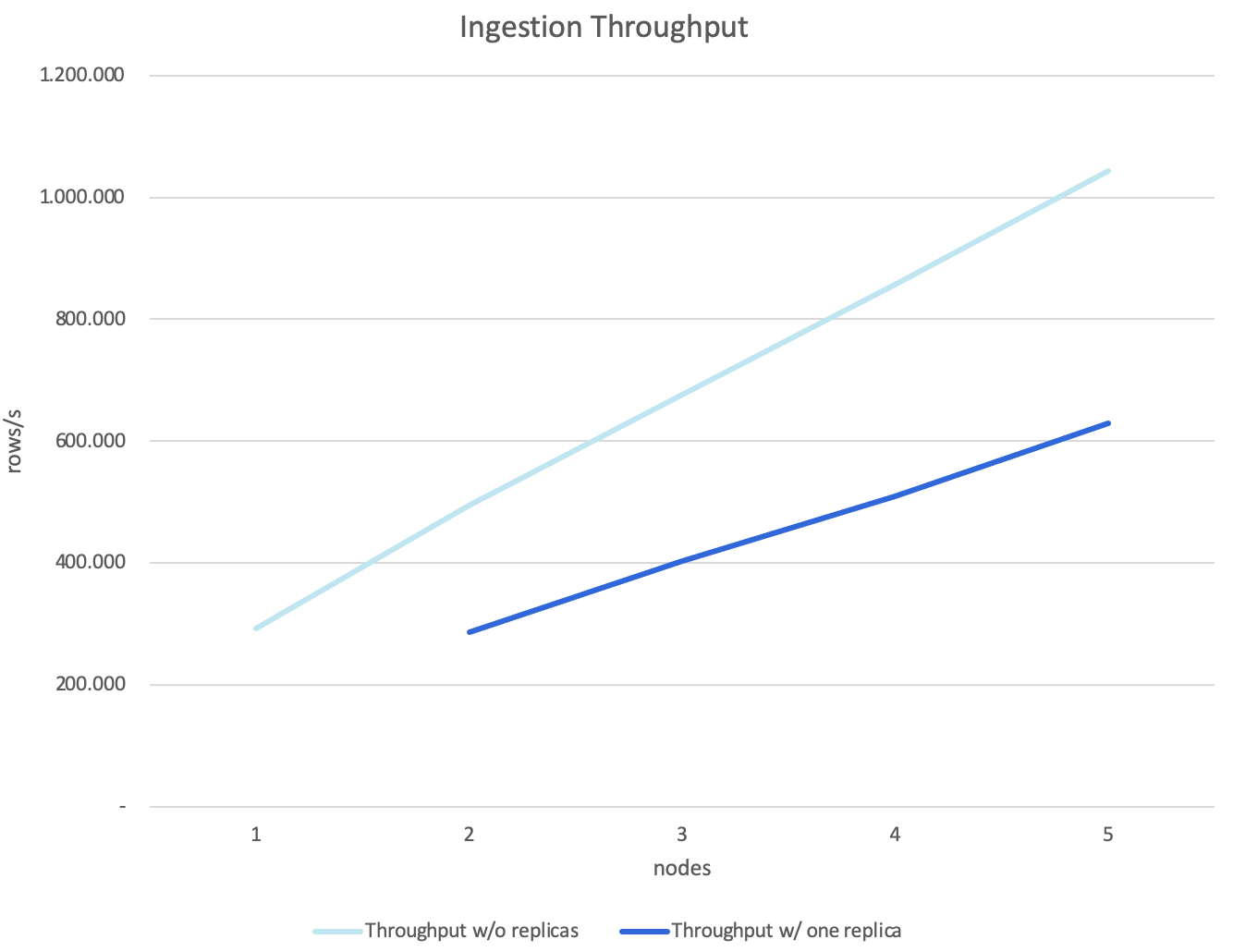
Ingest throughput on scaling from one to five CrateDB nodes
Assuming each node in the cluster contributed equally to the overall throughput, this equals a per-node throughput of 208,732 rows/s without replicas and 125,913 rows/s with one replica.
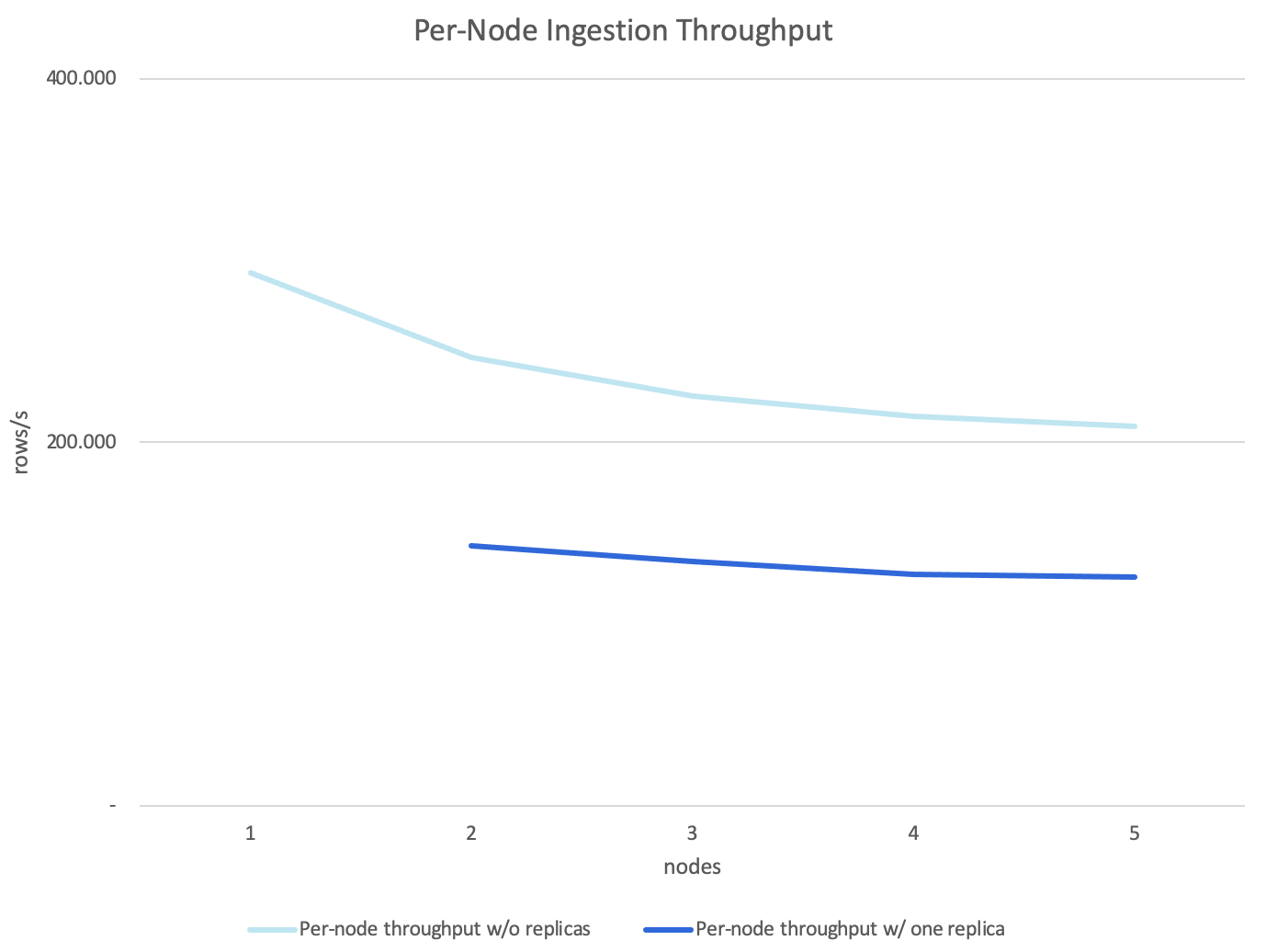
Ingest throughput per node on scaling
The conclusion
With every additional node, we simulated the addition of another ingestion process and saw a linear increase in throughput. With increasing cluster size, the throughput per node slightly decreased. This can be explained by the greater impact of node-to-node network traffic. The impact becomes less the bigger the cluster gets.
To take the node-to-node communication overhead into consideration, we reduce the projected throughput without replicas by 20% on each scaling (measured throughput before scaling * (1 + (0.8 * cluster size increase)). With one replica, throughput is consistently 40% below the measured throughput without replicas, so we calculate the expected throughput as expected throughput without replicas * 0.6.
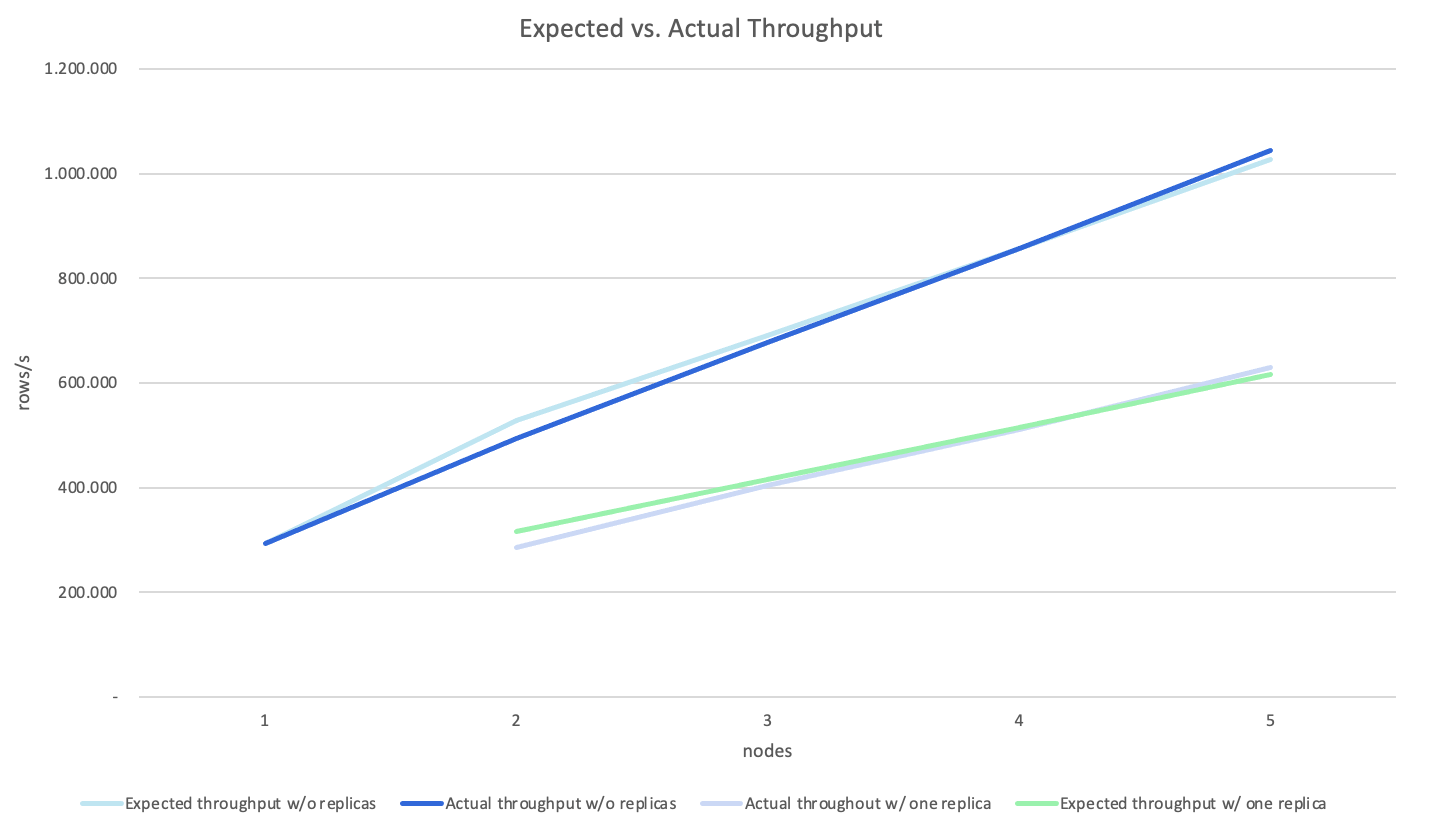
Expected vs. actual throughput, including overhead
Measured and expected throughput now match very closely, indicating that on each scaling, 20% of the cluster size increase is taken up by node-to-node communication. With one replica, even though two writes are performed for each row, we are only 40% lower than without replicas.
Despite the overhead, our findings still clearly show that scaling a CrateDB cluster is an adequate measure to increase ingest throughput without having to sacrifice indexing.
The learnings
We want to wrap up these results with a summary of the learnings we made throughout this process. They can serve as a checklist for your CrateDB ingestion tuning as well:
-
Disk performance: The disks storing CrateDB’s data directory must have enough throughput. SSD drives are a must-have for good performance, peak throughput can easily reach rates of > 200 MiB/s. Monitor your disk throughput closely and be aware of hardware restrictions.
-
Network performance: The throughput and latency of your network can become relevant at high ingest rates. We saw outgoing network throughput of around 10 GiB/s from the benchmark instance towards the CrateDB cluster. As node-to-node traffic increases while scaling, ensure it also provides enough performance.
When running in the cloud, certain instance types have restricted network performance.
When hosts have both public and private IP addresses, ensure to consistently use the private ones to prevent traffic needlessly being routed through the slower public internet. -
Client-side performance: Especially when generating artificial benchmark data from a single tool, understand its concurrency limitations. In our case with Node.js, we initially generated asynchronous requests in a single process, but still didn’t get the maximum out of it. In Node.js, each process is limited by a thread pool for asynchronous events, so only a multi-process approach was able to overcome this barrier.
Always batch your INSERT statements, don’t use single statements. -
Modern hardware: Use a modern hardware architecture. More recent CPU architectures have a performance advantage over older ones. A 16 CPU cores desktop machine will not be able to match the speed of a 16 CPU cores server architecture of the latest generation.


