In our last batch of work we extended the support for scalar subqueries to UPDATE and DELETE statements, and that work is now available in CrateDB 2.3.
In this post, I will introduce scalar subqueries, explain what challenges we faced extending this feature, and show you how we addressed those challenges.
Introduction
Scalar subqueries are SELECT statements which are embedded as an expression within another statement. They must return one row and can only return a single column.
Here's a simple example:
SELECT *
FROM my_table
WHERE x > (
SELECT value
FROM other_table
LIMIT 1
)
This is what is known as an uncorrelated scalar subquery, because the subquery does not reference columns from the parent relation scope. If the subquery had a WHERE clause that referenced my_table, for example, it would instead be a correlated scalar subquery.
CrateDB does not support correlated scalar subqueries at the moment, but support for uncorrelated scalar subqueries using SELECT (like the one above) has been available since version 0.57.0.
In version 2.3, we wanted to extend CrateDB's support for uncorrelated scalar subqueries to UPDATE and DELETE statements.
For example:
DELETE FROM locations
WHERE planet_id = (
SELECT id
FROM planets
WHERE name = 'Saturn'
)
Challenges
CrateDB has not previously had support for scalar subqueries in statements other than SELECT due to a mix of a short-sightedness, support for bulk operations, and an optimization to make operations on primary keys faster.
We'll explain all three factors in this section.
In the initial releases of CrateDB, clients could communicate with CrateDB using one of two protocols: HTTP or a binary transport protocol.
We'll ignore the binary transport protocol for this post. It’s not relevant to understand the problem and we replaced it with the PostgreSQL wire protocol in CrateDB 1.0. What’s important is how HTTP clients communicate with CrateDB, because that influenced some of our early design decisions.
Clients using HTTP send both the statement and any arguments in a single request, like so:
$ http :4200/_sql stmt="DELETE FROM t WHERE id = ?" args:='[1]'The above command uses the HTTPie tool.
Optionally, to support bulk operations, clients can specify multiple arguments, so that the statement is executed for each pair of arguments:
$ http :4200/_sql stmt="DELETE FROM t WHERE id = ?" bulk_args:='[[1], [2]]'Note that CrateDB has immediate access to all argument values, even when parameter placeholders are used in the statement. This fact led to a suboptimal decision in CrateDB's early design: to in-line the values into our analyzed statements.
To understand this, let's take a look at how statements are processed by CrateDB.
When CrateDB receives a statement, this statement is fed into the parser as a string and transformed into an abstract syntax tree (AST).
So, something like this:
DELETE FROM t WHERE id = ?Becomes this:
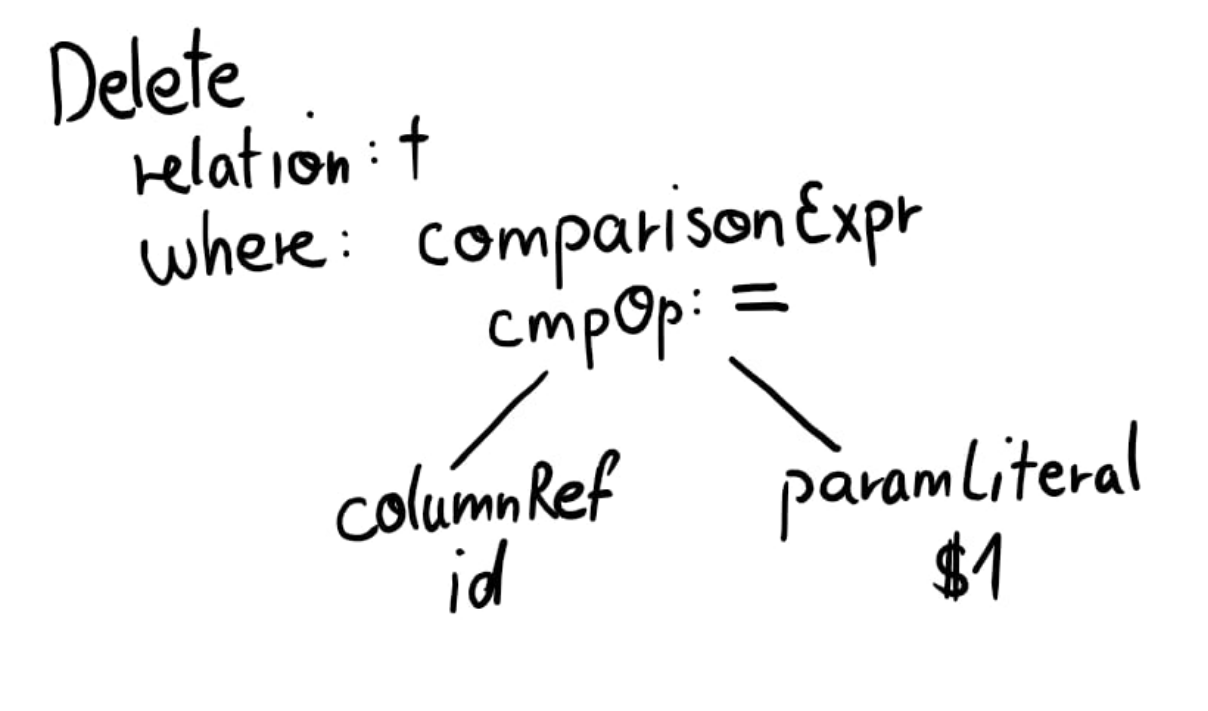
The next step is the analyzer.
The analyzer takes an AST and outputs what we call an AnalyzedStatement.
Traditionally, SQL databases do basic semantic validation and annotate the statement based on available metadata. So, for example:
- Does table
my_tableexist? (Validation) - Does table
my_tablehave a column namedid? (Validation) - What type is column
id? (Annotation)
CrateDB also performs these types of tests and annotations, but in addition, we also tried to detect certain optimization possibilities already in the analyzer. This had to be changed in order to support scalar subqueries for DELETE and UPDATE. The reason will be explained in a moment.
Since the expressions are being annotated with a type, we used this opportunity to immediately create a streamable structure. We call this Symbol. A Symbol is just a typed expression that can be serialized and deserialized.
Because we already had access to values for the parameter placeholders (the ? in the prepared statements which are turned into ParamLiteral objects as shown in the AST diagram above), we also immediately inlined the values into this typed expression tree.
The AST shown earlier is transformed into the following:
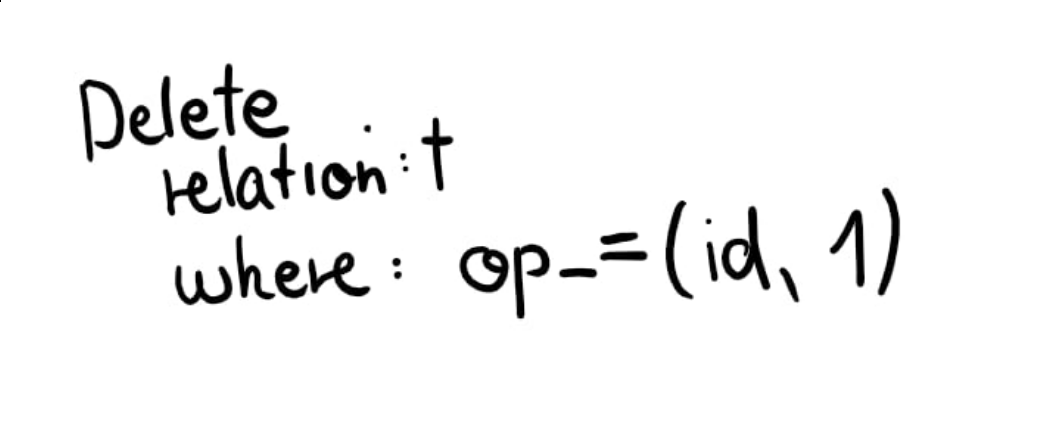
And in the case of DELETE bulk operation, we created a list of WHERE clauses:
![Delete relation:t where:[op_=(id,1),op_=(id,2)]](https://cratedb.com/hubfs/wp-content/uploads/2018/02/pasted-image-3.png)
In addition to that, we also analyzed the WHERE clause for equality comparisons on primary key and partitioned by columns. This information is used by the planner and optimizer to create optimized execution plans.
For example, if you have a table that is partitioned by month, and you execute a query like this:
DELETE FROM my_table WHERE month >= '2017-11-01'CrateDB tries to evaluate this query against all known partitions to determine which partitions this query could match. In the case of DELETE, this information can be used to optimize the execution plan by dropping whole partitions if the query doesn’t involve any other columns.
But to perform this optimization, access to the row values is mandatory.
However, take a query like this:
DELETE FROM my_table
WHERE month >= (
SELECT month FROM other_table WHERE ...
)
We cannot run the optimization step here, because the value for the scalar subquery isn’t available until it is executed.
Aside: the fact that we made this early design decision to substitute parameter placeholders with literals in the analyzer also turned out to be problematic when fully implementing the PostgreSQL wire protocol. With the PostgreSQL wire protocol, the query processing is done in multiple steps. First the client only sends a statement. Then it might ask for the types of all parameter placeholders. Only after this step, it sends the values for these placeholders. Due to our early analyzer design decisions, we weren’t able to support this flow. So certain clients didn’t work. (Not all clients depend on this functionality). Due to the changes explained below, we were able to support these scenarios.
Our Approach
So how did we set out to solve this?
In short: do less in the analyzer and more in the planner, optimizer, and executor.
To understand what that means, let's take a look at how scalar subqueries are being executed.
As mentioned in the introduction, uncorrelated subqueries do not refer to anything in their parent scope. That makes it possible to execute these kind of subqueries in an isolated fashion. So each subquery is executed individually first, and then afterwards the root query is executed.
Let us walk through how this works for a SELECT statement already shown earlier:
SELECT *
FROM my_table
WHERE x > (
SELECT value
FROM other_table
LIMIT 1
)
In this case the full execution plan is built up-front, including all subqueries. This works for SELECT because we don’t have to access any values in the statement to choose the execution plan.
The resulting (simplified) plan graph looks like this:
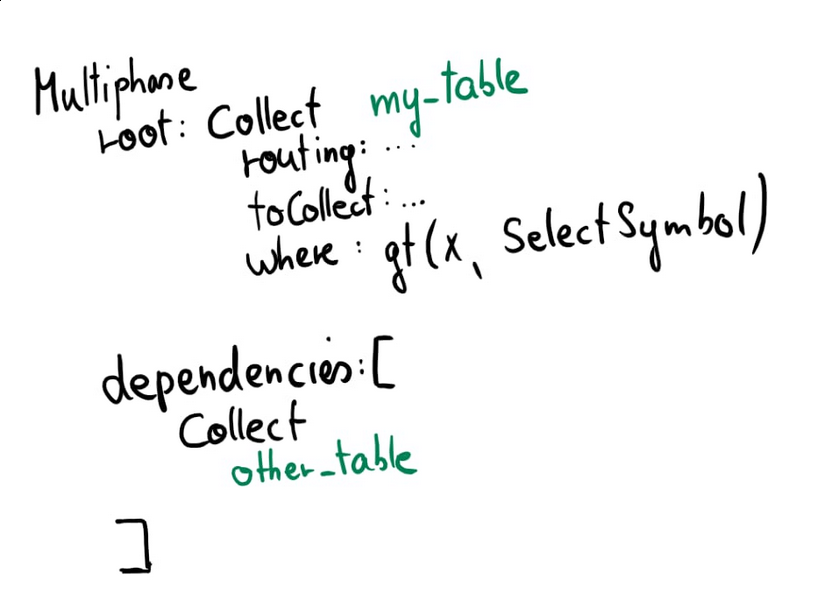
Multiphase is kind of a container plan that contains all planned subqueries in dependencies. The root relation plan is in root.
It’s important to note that in this case, the two Collect occurrences represent fully optimized and specific execution plans.
This plan is executed by first executing all dependencies (in parallel), and afterwards the root plan is executed:
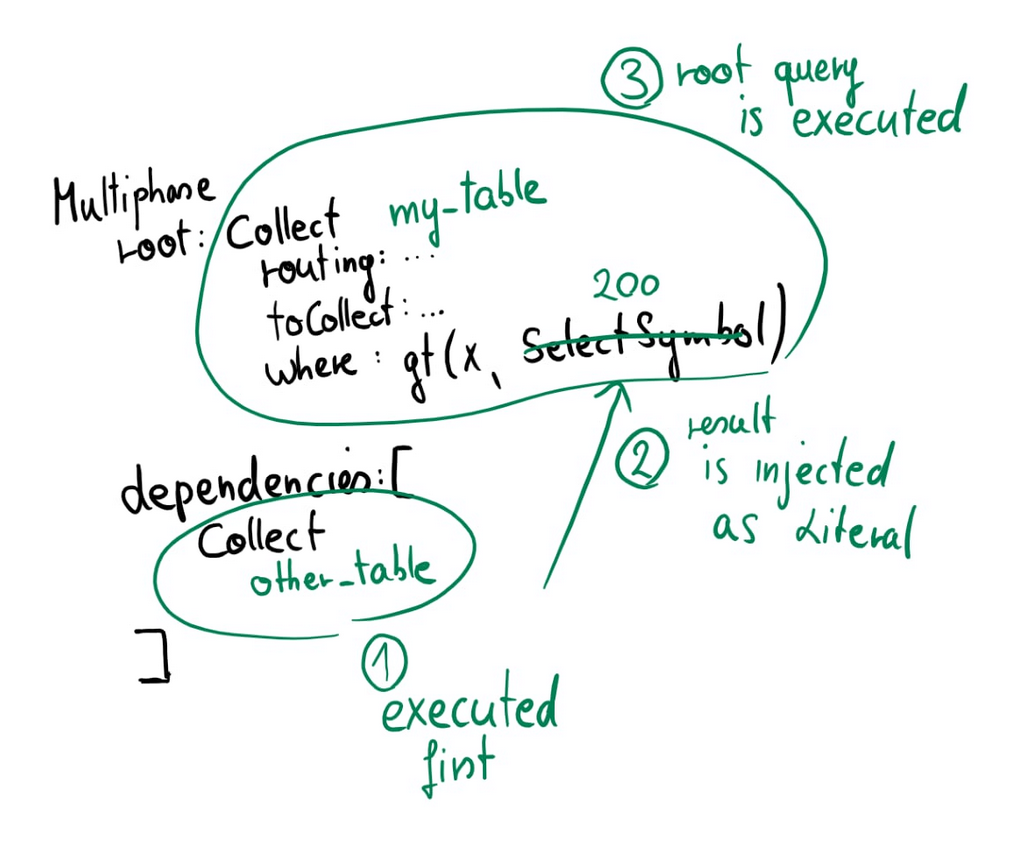
But to support scalar subqueries in DELETE and UPDATE statements, we wanted to interweave the planning and execution a bit more, with the goal of being able to do further optimization based on the values retrieved from the subquery execution.
Let’s walk through this based on the following DELETE statement:
DELETE FROM my_table
WHERE month >= (
SELECT month
FROM other_table
WHERE ...
)
Similar to the SELECT example, a Multiphase plan is created. But this time the Delete in the root attribute is only a “rough” plan. It basically says “delete this from my_table somehow”. It doesn’t (yet) specify how exactly. The dependencies include the subquery. In this case, it’s a Collect, which is already a specific execution plan.
![Multiphase root: Delete my_table where: gte(month, SelectSymbol) dependencies:[Collect other_table]](https://cratedb.com/hubfs/wp-content/uploads/2018/02/pasted-image-6.png)
The execution is similar to the SELECT example, with a subtle but important difference: after the subqueries are executed, the root plan is optimized before it is executed.
Let’s walk through it.
![Multiphase root: Delete my_Table where: gte(mont,'2017-10') dependencies: [Collect other_table]](https://cratedb.com/hubfs/wp-content/uploads/2018/02/pasted-image-7.png)
In this example, we can see that first the subquery, Collect, is executed (1). The result of this subquery are injected into the parent statement (2). If we wrote this out using SQL, the statement would look like this:
DELETE FROM my_table WHERE month >= '2017-10'Now the Delete plan can be optimized (3). In this case, month is a partitioned column, so the optimizer will create a specialized DropPartitions execution plan. This plan is executed as well and completes the statement execution (4).
Wrap Up
To add support for uncorrelated subqueries for DELETE and UPDATE statements in CrateDB 2.3, we moved logic that used to be in the analyzer further back, into the planner, optimizer and executor. CrateDB is now able to execute parts of a plan and then use the results of this partial execution to optimize and execute the remaining parts.
What's interesting about these changes is that they didn't increase the complexity of the code. In fact, we even reduced it a bit. That's a theme we've been able to observe a couple of times with SQL. Due to its composeable nature, we can often multiply functionality without increasing the complexity same way. (Testing is a different matter…)
I hope you enjoyed this lab notes post. Stay tuned for more like it.


