Introduction
In today's fast-changing AI landscape, the potential of Large Language Models (LLMs) has become increasingly important. These powerful AI systems have reshaped how we interact with information, offering vast knowledge from publicly available sources. However, as companies strive to improve their decision-making processes, they realize that LLMs' true value lies beyond their public capabilities. The challenge is clear: how can organizations utilize the potential of LLMs to analyze and extract insights from their proprietary enterprise data, seamlessly connecting it to other valuable data sources?
Two approaches have been emerging: Asking natural language questions to your data, the LLM identifies the relevant tables, generates an SQL statement, and gives an answer based on the results of the SQL query. We outlined this approach based on an SQL Database Agent of the LangChain Framework in our recent community post. The second approach, Retrieval Augmented Generation (RAG), provides context that is relevant to the question in prompts to an LLM and, therefore enables companies to use their unstructured data.
In this post, we will introduce the RAG approach based on CrateDB as a vector store and the OpenAI embedding model. Please note the sample code is also available in a Jupyter Notebook.
The role of vector store and vector similarity search
Vectors, numerical representations of data points, play a central role in transforming complex, mostly unstructured information into a format that machines can process efficiently. By converting textual information into vectors, we enable AI systems to efficiently organize data and search through complex datasets. In the context of LLM-powered data analysis, vector stores have emerged as crucial solutions to data management. Unlike traditional approaches, vector stores embrace a high-dimensional, numeric representation of data, enabling efficient and flexible data retrieval and analysis, i.e. providing domain-specific or company-specific information to LLMs.
One of the most compelling applications of vector stores lies in similarity search, particularly through the k-nearest neighbors (KNN) search algorithm. KNN search leverages the vector properties to identify the k-most similar data points to a query vector, enabling applications like recommendation systems, image retrieval, or anomaly detection. We will illustrate how the KNN search aids the process of retrieval augmented generation by enhancing the quality and relevance of generated content.
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation is a technique for retrieving more accurate, higher quality responses than a generative LLM can do on its own, due to external sources of knowledge used to supplement the LLM’s representation of data.
In the following example, we will use CrateDB as a backbone for efficient data storage of both structured and unstructured data, as well as vector data generated by popular embedding algorithms. Before building out a RAG system, it is important to understand the key components and tools that make the process possible:
- LLM: the core AI model responsible for generating responses from the corpus of public and private data
- Vector store: the search engine of the system. It fetches relevant documents by comparing how similar their vector representation is compared to a query vector
- Embedding algorithm: before storing and retrieving data we need to convert textual information into a format that the system can understand. We rely on existing embedding algorithms to transform the text into vector representations.
- User prompt: serves as the initial instruction to the AI model to generate content based on the user’s needs
- User input: a query or question provided by the user
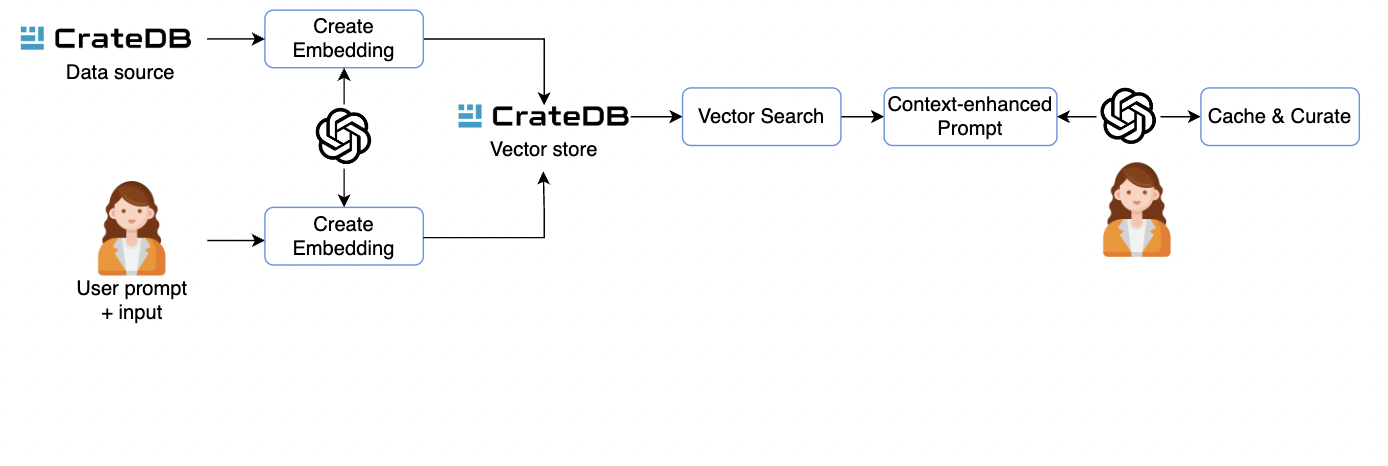 Figure 1: RAG workflow with CrateDB
Figure 1: RAG workflow with CrateDB
Figure 1 shows the high-level overview of the RAG workflow with CrateDB. The first step is to identify the key data sets for training and a high-quality prompt to drive the content generation. In the second step, we build our knowledge-based index, a vector representation of data used to optimize the retrieval of information from a large collection of data. Once this process is complete, we fetch the relevant documents from the vector store based on a search algorithm. The aim is to identify the most relevant documents that likely contain the information requested by a user.
Finally, that we have all the components in place, we can pass the documents, the question, and the prompt to the LLM to return a response.
Vector store in CrateDB
In CrateDB, vectors are supported with float_vector data type, which allows the storage of dense vectors of fixed length. The vector store and vector search in CrateDB are based on Lucene’s solution for the storage and analysis of numerical vectors. CrateDB effectively indexes and manages high-dimensional vector data, which enables fast and accurate similarity search, making it an optimal database solution for real-time applications.
With the vector store in CrateDB, one can harness the combined power of a multi-model database and advanced vector handling, offering a comprehensive platform for managing and querying vectorized data in combination with structured and semi-structured data efficiently.
LLM augmentation with CrateDB data: example
The implementation of the RAG system consists of two major steps:
- Document indexing: in this step documents (e.g., pdf, excel, or docx) are parsed into row text and indexed.
- Retrieval: in this step, we send the user question together with a similar context from parsed documents to LLM (e.g., GPT-4). The LLM will use the inputs to provide an answer.
Now, let’s take a closer look at each step. For clarity reasons, we will illustrate only the significant implementation details.
Document indexing
To augment the LLM, we choose information from the white paper Time-series data in manufacturing that provides a good overview of the database technologies for storing and analyzing time-series data. In the first step, we use the LangChain pydf library, a common pdf parsing library, to parse the pdf file to text. We split the text into chunks of approximately 1000 characters - with 200 overlapping characters between each chunk. Usually, the size of a chunk depends on the application, and in our use case it proves to be an excellent starting point:
Now, for each piece of text, we generate the OpenAI embeddings, create a data frame that holds the generated data, and store the data frame in the CrateDB database:
Note that we use the SQLAlchemy engine to establish the database connection and execute an SQL statement to create a table in CrateDB. The engine uses the connection information from dbname and disables the echoing of SQL statements for a cleaner output. After the table is created, we use the to_sql API in the pandas library to insert data into the newly created table.
Retrieval
We have just seen how to store vector data in CrateDB with a few lines of code. To get some interesting information from our data source we utilize a knn_match interface in CrateDB. As we indexed a document about time-series databases, our question came around this topic:
As illustrated in Figure 1 we send relevant knowledge to LLM by finding vectors in our database which are similar to the vector representation of our question.
Using these similar documents, we can finally send them alongside our question to the LLM. At this step, we instructed our LLM with a short but concise and clear system message.
After processing the augmented prompt, the LLM generates and returns its response.
To check the full implementation and response and to try out other questions in the domain of time-series databases check out our implementation.
Conclusion
In this example, we demonstrate how to give more knowledge to LLM to get answers to domain-specific questions. Frameworks, such as LangChain empower developers to create cutting-edge AI applications by leveraging a vast number of models. When combining the strengths of language models with vector store in CrateDB, you can build advanced applications that go beyond generic responses.
If you are excited about the potential of CrateDB and want to explore further its capabilities, try out a free-forever cluster on CrateDB Cloud. If you have any questions please check our documentation and join our growing community.


