In this article, we focus on replicating data from DynamoDB in real time to CrateDB, using Change Data Capture (CDC) events.
Architecture
To be cloud-native, we only want to use AWS services to implement our data pipeline. We will use the following services:
- DynamoDB: The starting point where data resides and is actively changed through INSERT, UPDATE, or DELETE statements.
- Kinesis: DynamoDB will ingest CDC events into Kinesis as a message queue.
- Lambda: CDC events must be decoded, interpreted, and translated into standard SQL. Lambda is a perfect fit to carry out such compute tasks in a serverless mode.
- Elastic Container Registry (ECR): To facilitate testability and dependency management of our Lambda function, we bundle it as an Open Container Initiative (OCI) image that we push to an ECR repository.
- CloudFormation: To be production-ready, we will deploy all components as a CloudFormation template, following the Infrastructure as code (IaC) paradigm.

Lambda Function
The core component of our CDC replay solution is the Lambda function. In a simplified way, it works as shown below. The two core dependencies used are:
- commons-codec: Provides the logic to transform a DynamoDB CDC event into a CrateDB-compatible INSERT, UPDATE, or DELETE statement.
- crate: The CrateDB HTTP driver for sending SQL statements to CrateDB.
The handler method gets invoked when a new batch of events arrives from Kinesis. We iterate through each of the events and forward them to CrateDB:
A more sophisticated version of the Lambda function can be found on GitHub.
Deployment
To set up our data pipeline, we use cratedb-toolkit. The toolkit is Python-based and includes a set of subsystems to conveniently carry out common tasks, ranging from data imports to date retention policy enforcement. In our case, it takes care of provisioning the CloudFormation template, building the OCI image, as well as deploying it.
After installing it with a simple pip install --upgrade "cratedb-toolkit[kinesis]", we can create our resources programmatically.
We start with saving the above Lambda function as kinesis_lambda.py and build an OCI image. The image gets pushed to ECR.
We can find the image on ECR when navigating to our repository:

Next, we define the DynamoDB table, Kinesis stream, Lambda function and connect all of them. The Lambda function also points to our CrateDB Cloud target cluster.
When navigating to CloudFormation in the AWS console, we can now see all our services deployed:
A full version of the provisioning script can be found on GitHub, together with exact step-by-step instructions.
Finally, in CrateDB Cloud, we provision the target table with a simple CREATE TABLE statement. We encapsulate the JSON payload into CrateDB’s OBJECT container data type that fully indexes all JSON properties: CREATE TABLE transactions (data OBJECT(DYNAMIC));
Execution
To populate the DynamoDB table with some initial data, we use the AWS CLI:
Querying the CrateDB sink table shows the data showing up almost instantly:
Summary
We have shown that DynamoDB CDC events can be processed and replayed to CrateDB through native AWS services. cratedb-toolkit provides ready-to-use automation that connects all components and simplifies deployment.
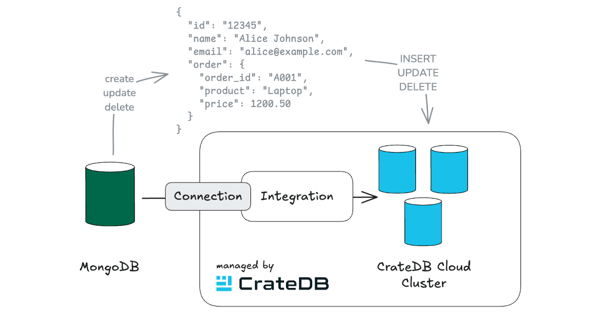
While this particular example focused on DynamoDB CDC events, the approach is universal by retrieving events from Kinesis, and can also be applied to other source systems for CDC events, such as MongoDB.