As data volumes grow, managing large tables efficiently becomes critical for both performance and maintainability.
CrateDB uses partitioning to divide tables into smaller, manageable segments — called partitions — each consisting of one or more shards. This approach improves query performance, simplifies data lifecycle management, and makes it easier to retain or archive historical data without impacting current workloads. Partitioning is particularly useful for time-series or event-driven data, where new records continuously arrive while older data becomes less frequently accessed.
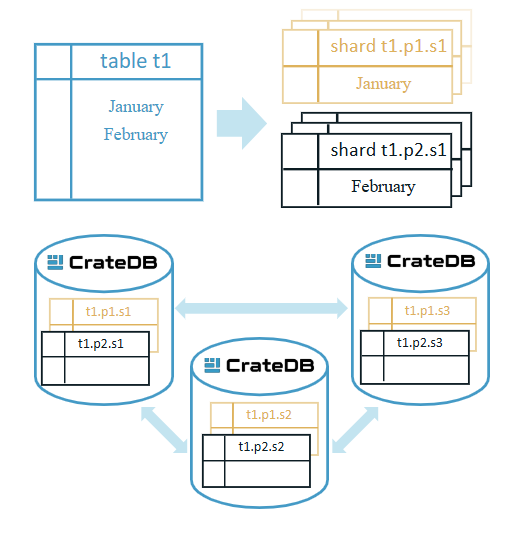
How partitioning works
In CrateDB, each table partition behaves like a separate table under the hood, with its own shards and metadata.
- Automatic creation: When data with a new partition key value (for example, a new month) is inserted, CrateDB automatically creates a corresponding partition.
- Shard-based efficiency: Each partition is divided into a defined number of shards, which CrateDB uses to parallelize ingestion and queries.
- Flexible configuration: You can adjust the number of shards for future partitions to match your workload as it grows.

Benefits of partitioning
Partitioning is a key technique for keeping performance consistent as datasets expand.
- Accelerated queries: SQL filters automatically identify the relevant partitions, so CrateDB only searches the data that matters, drastically reducing query latency.
- Faster deletes: Removing old data is easy and fast; entire partitions can be dropped instantly without affecting other data.
- Archiving support: You can close partitions that no longer need to be queried but must remain stored for compliance or audit purposes. Closed partitions are ignored by the query planner but still available for recovery or reactivation.
- Independent backup and restore: CrateDB’s incremental backup system operates at the partition level, enabling selective backup and recovery of partitions as needed.
Common partitioning strategies
The most common partitioning strategy in CrateDB is time-based partitioning, which organizes data by time intervals such as month, quarter, or year. Example use cases:
- Time-series data: Store recent data in active partitions (e.g., current month) and archive older partitions for compliance.
- IoT analytics: Organize sensor data by time to optimize ingestion and queries.
- Log management: Partition by date to efficiently drop or archive old logs.
Partitioning and sharding
Together, partitioning and sharding form the foundation of CrateDB’s scalability, combining logical data separation (partitions) with physical data distribution (shards).
As your dataset grows, you can increase the shard count for new partitions, enabling seamless horizontal scaling without downtime or manual intervention.
Why partitioning matters
- Faster queries through partition pruning.
- Simplified data lifecycle with easy retention and deletion.
- Scalable growth by adjusting partition and shard parameters over time.
- Operational flexibility to archive, back up, or restore data by partition.
- Cost efficiency through selective storage and retention strategies.

