What We Learned Hosting Our First-Ever Devops Workshop
We hosted our first-ever devops workshop with the help of PyLadies This post tells you what we did and what we learned in the process.
We hosted our first-ever devops workshop with the help of PyLadies This post tells you what we did and what we learned in the process.

You don't have to choose between operational historians or a time-series database for industrial IoT. There's a third option.
A real-life example of applied machine learning to prevent critical events in a hydroelectric power plant. Part two of the series.
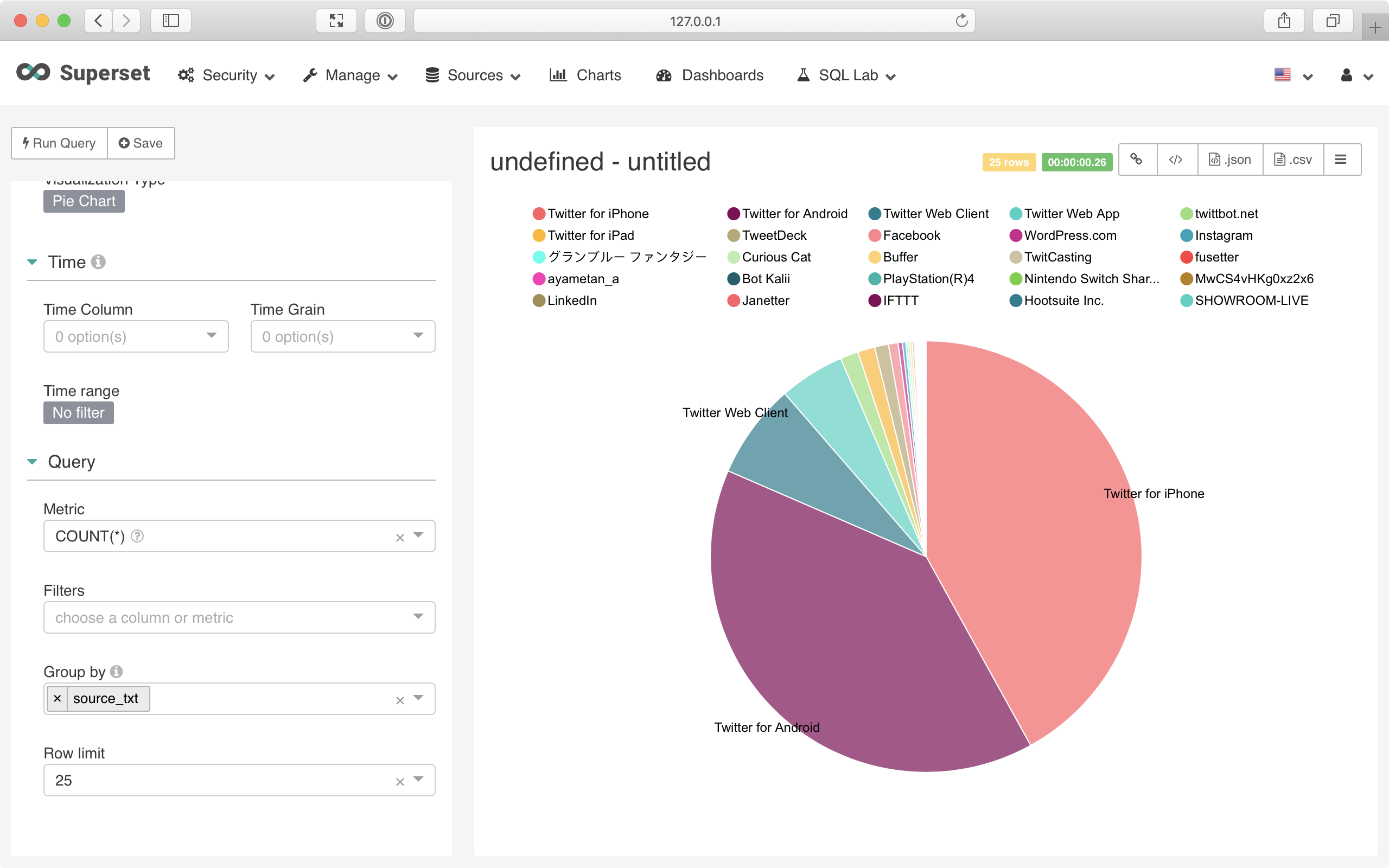
This step-by-step tutorial shows you how to get started with CrateDB and Apache Superset, a BI tool for easily organize your data.

Some of the highlights from the J on the Beach 2019. With talk videos, some personal reflection, and links to further reading.

Earlier this month Crate.io was named a "cool vendor" in the Gartner 2019 Cool Vendors in Manufacturing Operations report.
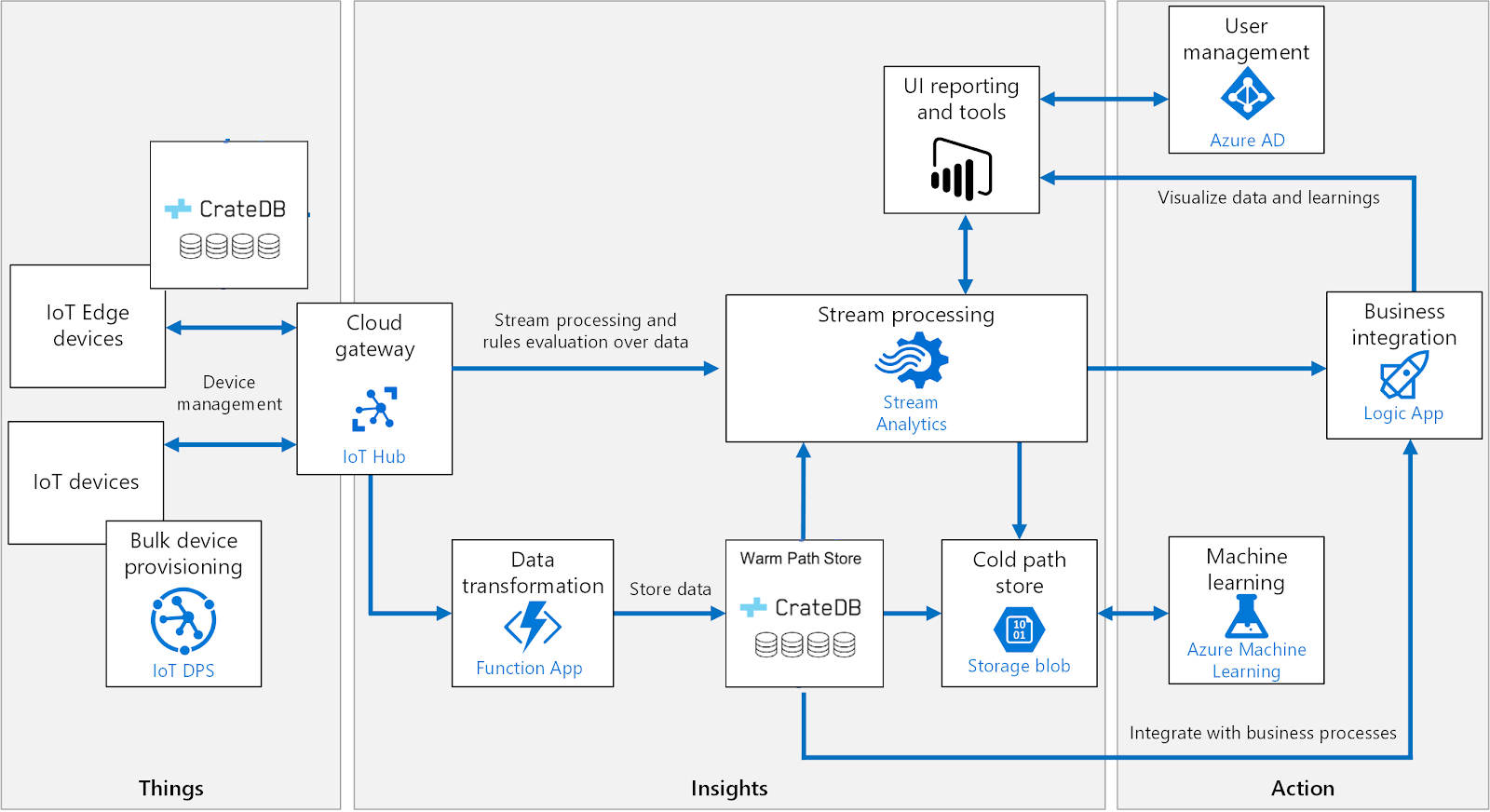
We explain how CrateDB fits into the Azure IoT ecosystem and how it can be used to supercharge your Azure tech stack.

In this post, I will introduce you to the idea of doing data science for the common good and hopefully give you a few ideas about how you can get started.

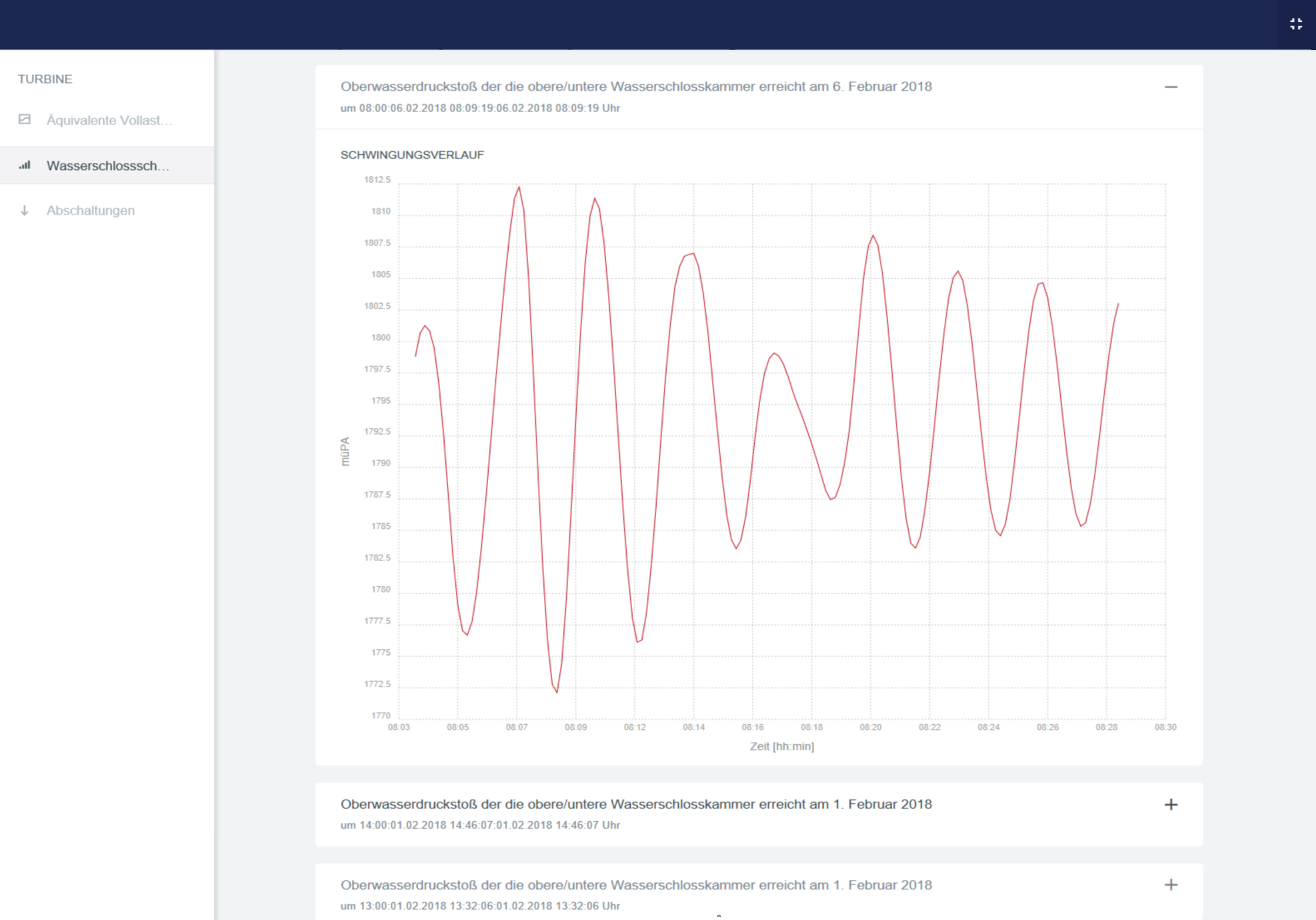
An overview of a proof-of-concept we have been working on with Craftworks to deliver business intelligence for one of Illwerke VKW's key hydroelectric power plants.
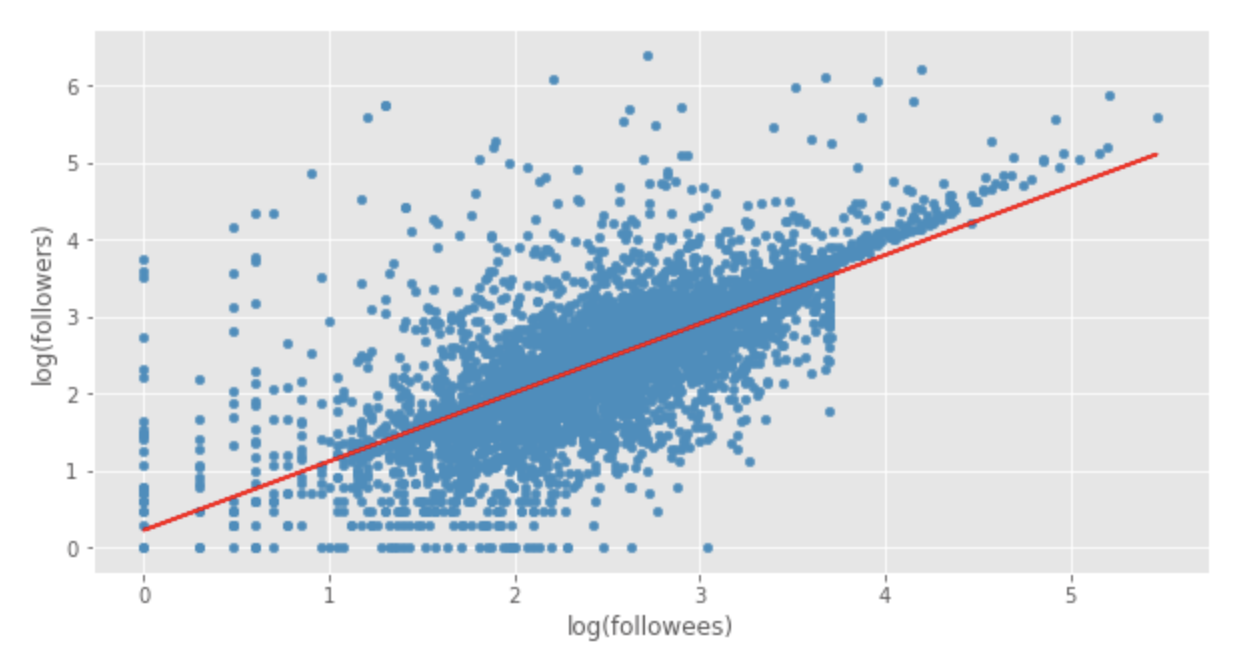
In the third part of this miniseries, I show you how to predict the number of Twitter followers a user has using regression analysis.