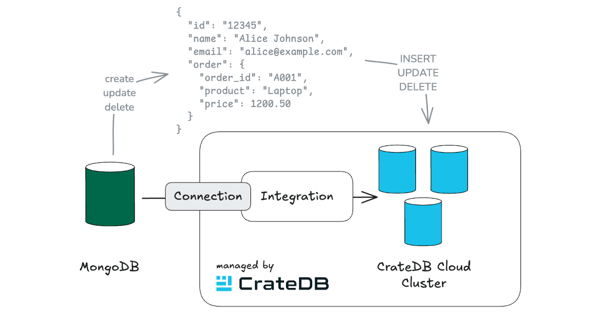
The CrateDB Cloud has significantly enhanced its capabilities throughout this year, particularly with the introduction of its versatile import functionality. This powerful feature now allows users to import data from various sources directly into their CrateDB Cloud clusters with a few clicks. Here's a summary of the advancements that we delivered so far:
Comprehensive Import Functionality in CrateDB Cloud
The import system now boasts an array of functionalities that cater to a wide range of data sources and formats, significantly streamlining the data integration process for CrateDB Cloud users.
Data Sources
-
Local File Import: Users can upload files from their local systems, streamlining the process of integrating offline data.
-
URL Import: Enables the import of data files hosted on web servers, facilitating easy access to online datasets.
-
S3 and Compatible Services: This feature allows the import of data from most S3-compatible storage service (AWS S3, DigitalOcean spaces, CloudFlare R2 and many more), enhancing flexibility and compatibility with a wide range of cloud storage solutions.
-
Azure Storage Containers: The latest addition, allowing users to import data directly from Azure Storage containers, broadening the range of cloud services that integrate seamlessly with CrateDB Cloud.
Supported File Formats
- Parquet, JSON, NDJSON and CSV: These common data formats are supported, ensuring that the majority of data types and structures used in modern data analytics can be easily imported.
Automatic Schema Inference
CrateDB Cloud simplifies data integration with its automatic schema inference, reducing setup time by intelligently mapping imported data to corresponding CrateDB types. It defaults to OBJECT(IGNORED) for object types to handle heterogeneous schemas, but also allows manual table creation with specific type mappings for homogeneous data. This feature balances automation with customization, streamlining data preparation for users.
Security Focus
Security is paramount, especially in data import processes. Sensitive information like access keys, connection strings or SAS tokens are handled with the highest security standards.
Export Capabilities
CrateDB Cloud also offers robust export features, supporting the same formats as imports (JSON, JSON-Lines, CSV, Parquet). Although currently limited to 1 GiB in size, these exports can be downloaded and used for various purposes.
Introducing Multi-File Imports
CrateDB Cloud now supports importing multiple files at once, a feature that greatly enhances the efficiency of handling large data sets.
How Multi-File Imports Work
-
Glob Patterns for Efficiency: Users can now use glob patterns to import multiple files simultaneously from S3-compatible storage and Azure Storage containers. This feature is particularly useful for services that generate numerous files with common naming conventions, like AWS CloudTrail or Segment.
Example Use Case - CloudTrail Logs
For example, in handling CloudTrail logs, you can use a globbing pattern such as CloudTrail/us-east-1/2023/11/12/*.json.gz to import all pertinent log files for a given day. The pattern /2023/11/12/ facilitates the upload of files from that specific day. Similarly, using /2023/11/* allows for the upload of files from the entire month. This approach significantly streamlines the import process, enabling the efficient import of logs from a specific month or even an entire year with a single globbing pattern.
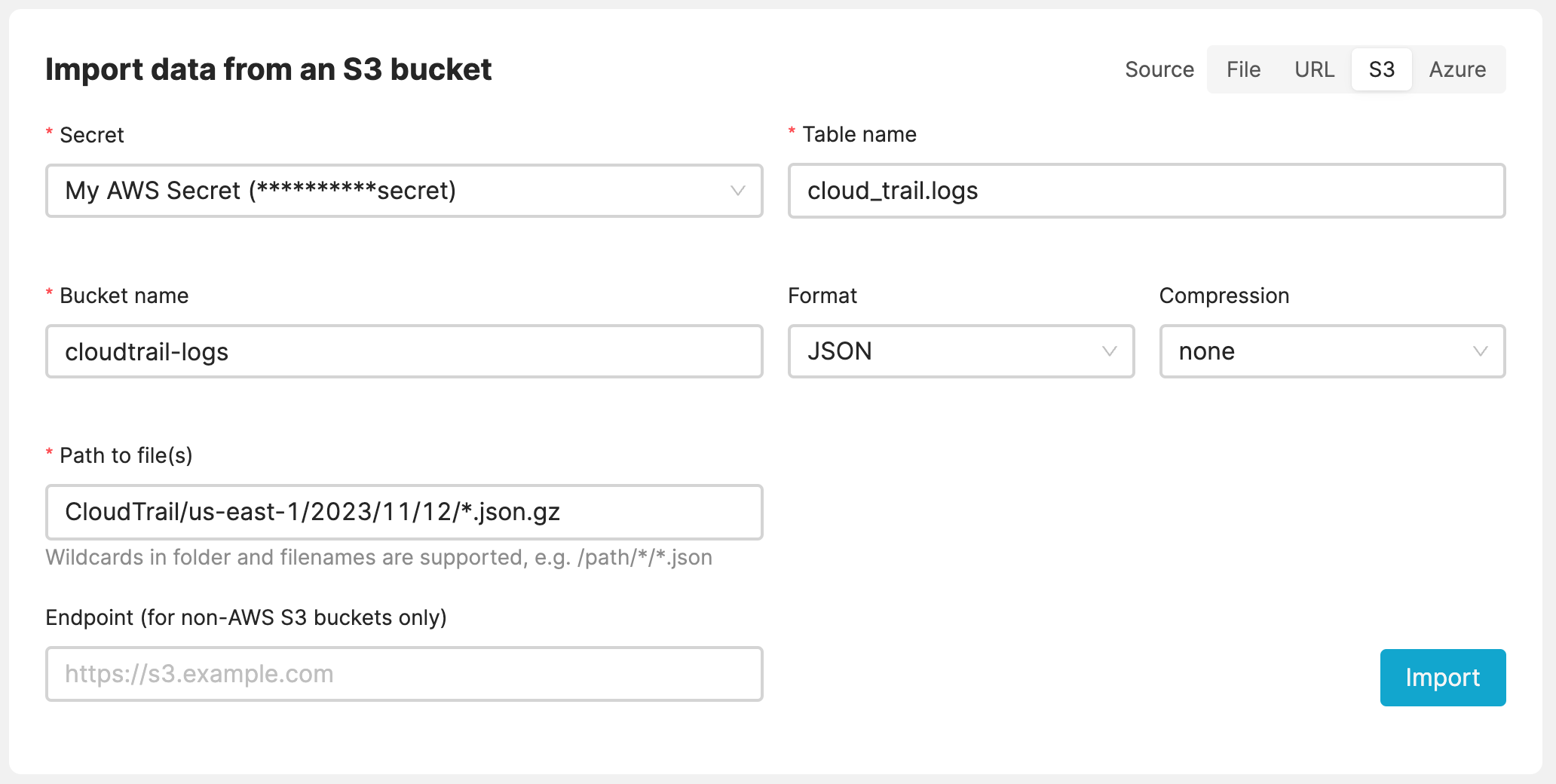
Import CloudTrail Logs from S3 bucket
Conclusion
Explore CrateDB Cloud and its import functionality by visiting https://console.cratedb.cloud to start your free CrateDB cluster today. For full details of the import/export system, visit our documentation.