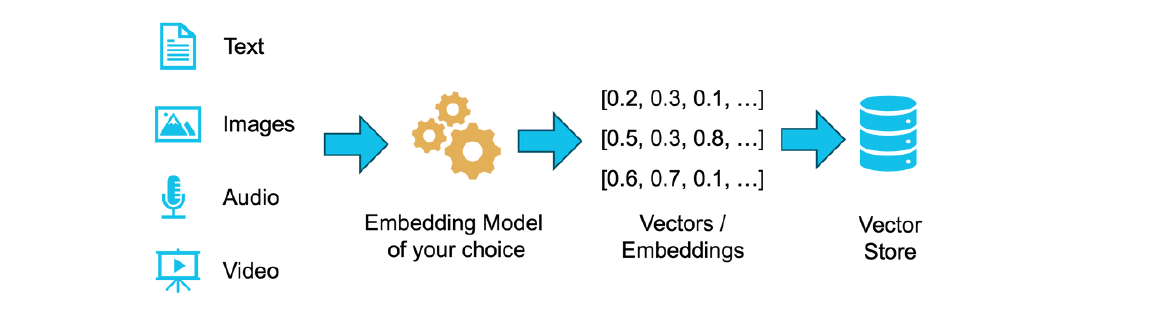
In the context of Generative AI, multimodal vector embeddings are getting more popular. No matter the kind of source data—text, images, audio, or video—an embedding algorithm of your choice is used to translate the given data into a vector representation. This vector comprises numerous values, the length of which can vary based on the algorithm used. These vectors, along with chunks of the source data, are then stored in a vector store.
Vector databases are ideal for tasks such as similarity search, natural language processing, and computer vision. They provide a structured way to comprehend intricate patterns within large volumes of data. The process of integrating this vector data with CrateDB is straightforward, thanks to its native SQL interface.
CrateDB offers a FLOAT_VECTOR(n) data type, where you specify the length of the vector. This creates an HNSW (Hierarchical Navigable Small World) graph in the background for efficient nearest neighbour search. The KNN_MATCH function executes an approximate K-nearest neighbour (KNN) search and uses the Euclidean distance algorithm to determine similar vectors. You just need to input the target vector and specify the number of nearest neighbours you wish to discover.
The example below illustrates the creation of a table with both a text field and a 4-dimension embedding field, the record insertion into the table with a simple INSERT INTO command, and the usage of the KNN_MATCH function to perform a similarity search.
