Run Your First CrateDB Cluster on Kubernetes, Part One
Part one of a miniseries that walks you through the process of setting up your first CrateDB cluster on Kubernetes.
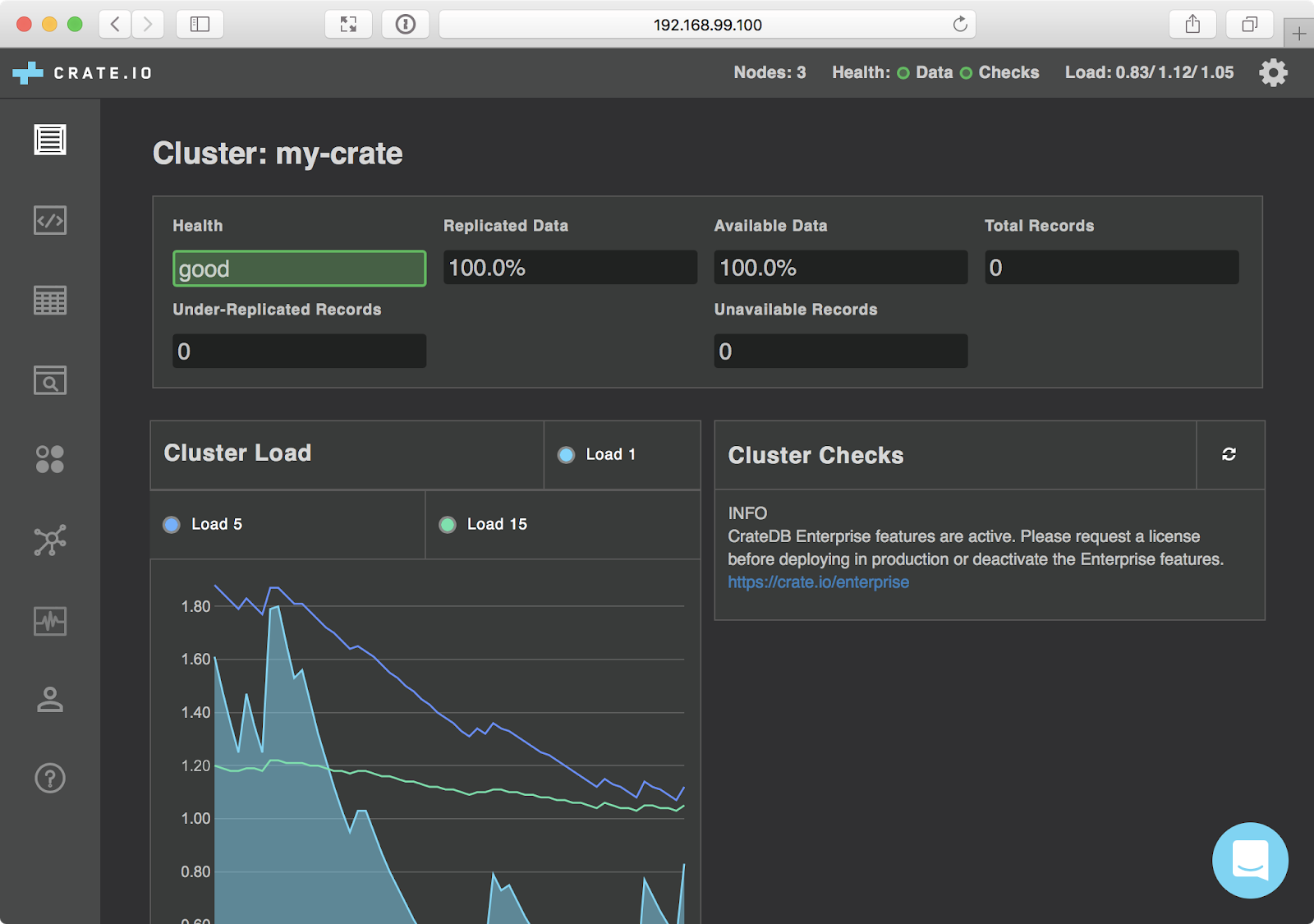
Part one of a miniseries that walks you through the process of setting up your first CrateDB cluster on Kubernetes.
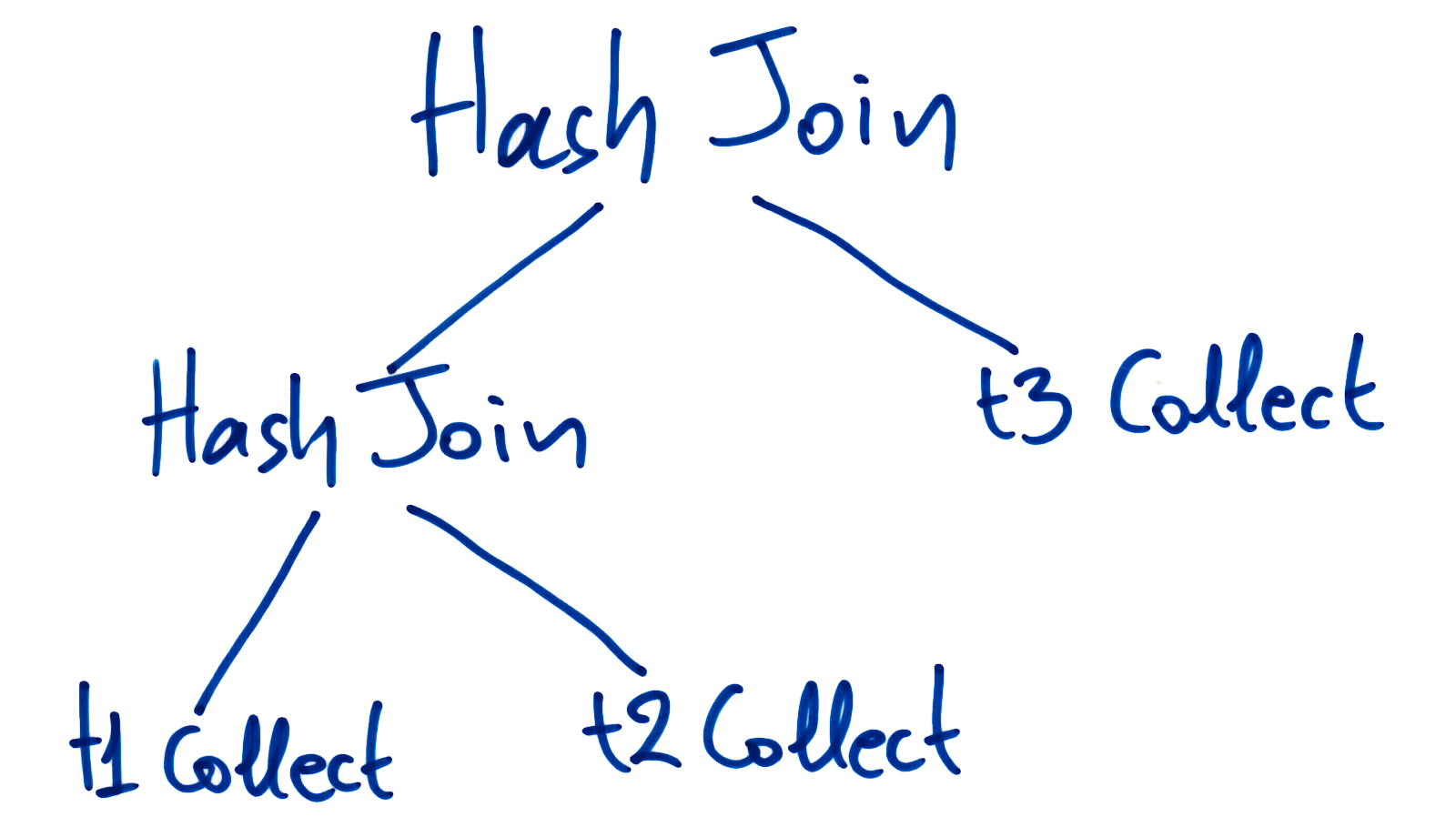
This is part two of a three-part miniseries that looks at how we improved join performance in the CrateDB 3.0 release.

Last month, three of us flew out for J on the Beach in Málaga, a conference for bringing "developers and DevOps together around Big Data."
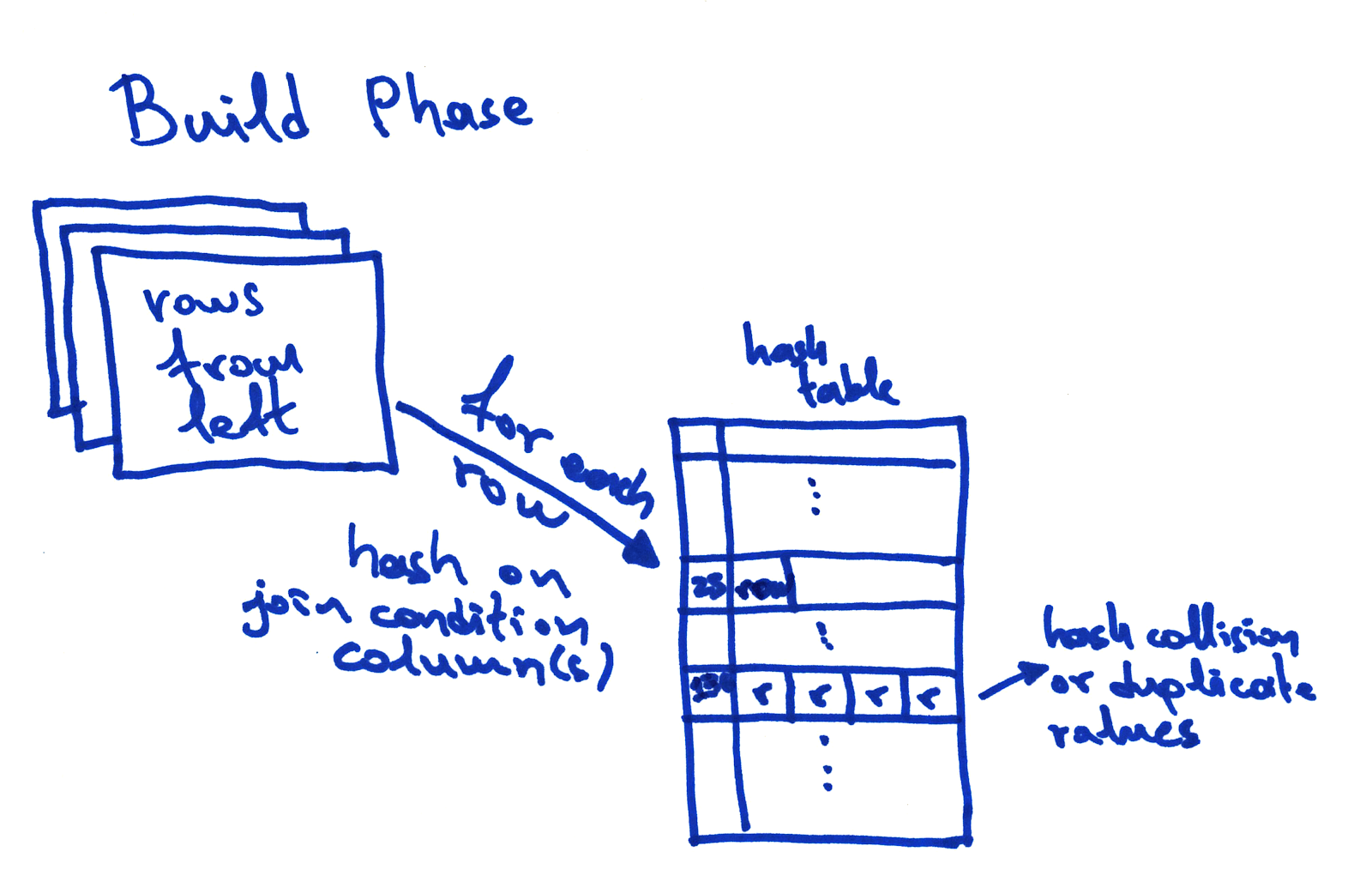
We made faster joins by implementing a block hash algorithm and distributing its execution across the cluster. Find out more in this post.

Crate.io takes data protection very seriously. We started work months ago to make sure we are compliant with the GDPR. Here's what we've been up to so far.
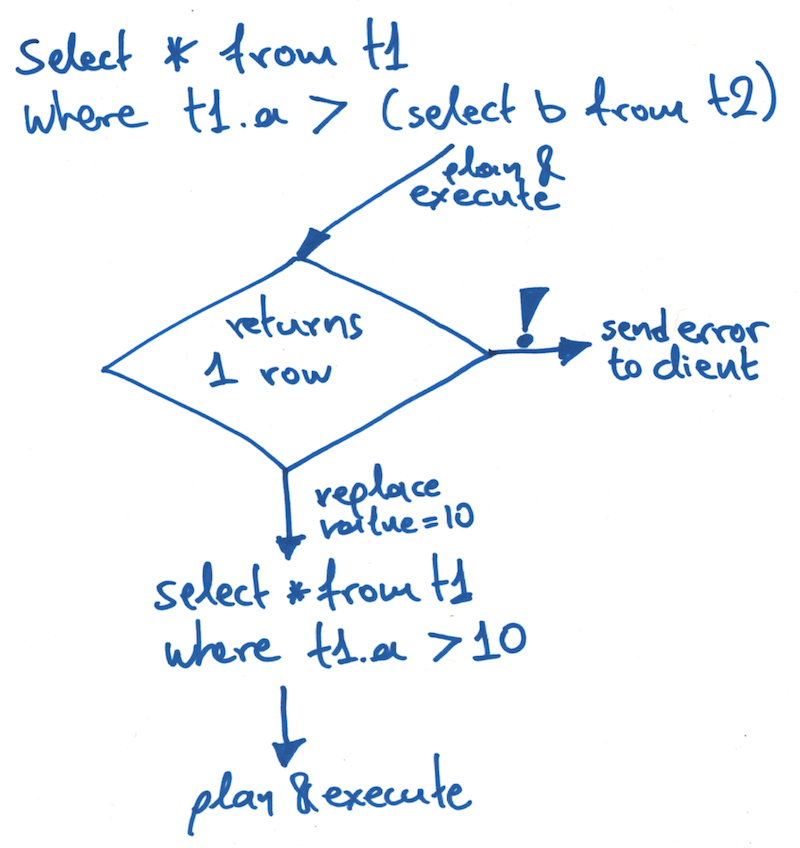
We recently added support for multi-row subselects. Memory can cause bottlenecks, but fortunately, we found the solution.
The CrateDB 2.3.x release line is stable now, so head on over to the downloads page to get started. In this post, I will take a closer look at some of the other new features in 2.3.

The rise of distributed SQL databases has revolutionized application architecture, allowing scalability & flexibility without sacrificing the SQL power.
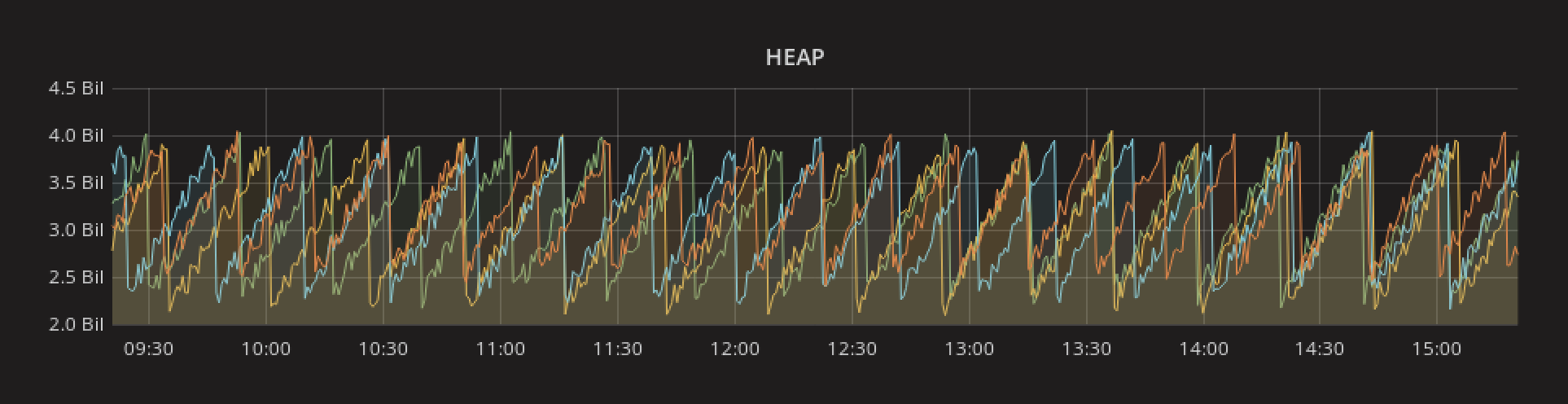
In this post we will show you what to look at when you're monitoring a distributed java application.
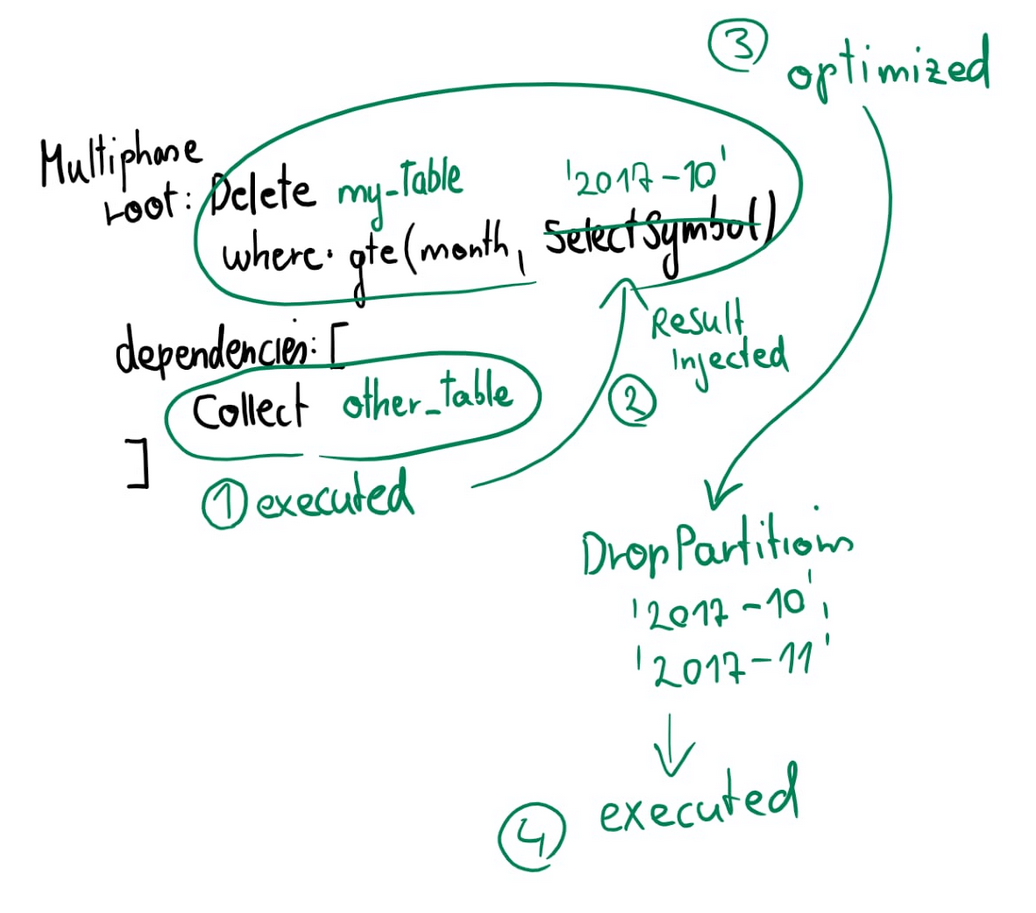
In this post, I will introduce scalar subqueries, explain what challenges we faced extending this feature in CrateDB, and then show you how we addressed those challenges.