Over the past decade, engineering teams have adopted a growing list of specialized databases: time series engines for metrics, search systems for text, document stores for JSON, vector databases for embeddings, columnar warehouses for analytics, and more. Each tool excels at a specific workload, but taken together they create a complex and fragmented ecosystem.
This fragmentation becomes a challenge when applications generate several data types at once, or when teams need to combine logs with metrics, vectors with documents, or geospatial signals with real time events. Modern data products rarely fit into neat boxes anymore.
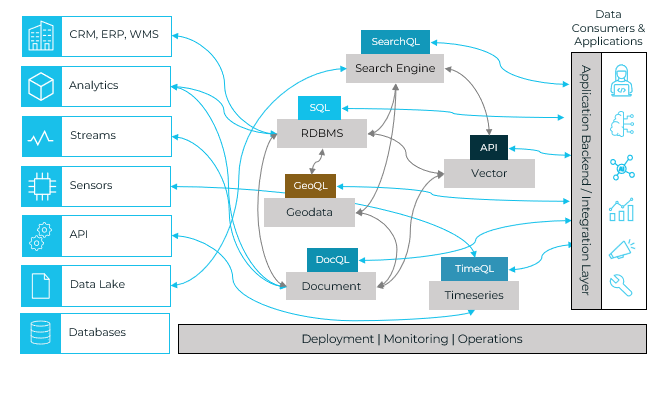
This is why a unified real time analytics database has become so attractive. Instead of juggling multiple platforms, a single engine built for diverse data types and mixed workloads helps teams simplify their architecture, reduce operational overhead, and unlock richer insights.
This article introduces several major database categories and shows where a unified database approach can streamline the work engineers do today.
Time Series Database
Time series databases specialize in handling continuous, timestamped data streams such as metrics, sensor values, financial ticks, or IoT telemetry. They are optimized for rapid ingestion and time based aggregations across massive append-only datasets.
A unified approach gives you the same strengths while avoiding siloed tooling. CrateDB provides native time series functions, automatic indexing, and high performance columnar storage so teams can analyze events in real time without deploying a standalone TSDB.
Read more on how CrateDB handles time series data modeling for real-time analytics at scale.
Geospatial Database
Geospatial engines are built to store coordinates, calculate distances, perform geofencing, and run spatial joins. These operations power applications such as fleet tracking, logistics, smart mobility, and location intelligence.
With built-in geospatial types, indexing, and functions, a unified system lets teams mix geospatial queries with metrics, logs, or device signals in one place, eliminating the need for a dedicated mapping database.
Read more on the best geospatial databases and how CrateDB can be used as a geospatial database for real-time analytics.
JSON Database
JSON databases emerged to accommodate semi-structured data with evolving schemas and nested properties. They are helpful when applications generate complex documents rather than fixed relational records.
A unified database that supports JSON natively inside SQL lets engineers store flexible structures while still joining them with tabular data, filtering them efficiently, and running analytical queries without exporting to another system.
For a practical example of how this works at scale, see how CrateDB handles JSON data for real-time analytics.
Vector Database
Vector databases power similarity search for embeddings, semantic retrieval, and RAG workflows. They make it possible to compare meaning rather than exact keywords, which is essential in AI systems.
A unified engine that stores vectors alongside time series data, documents, events, or geospatial metadata enhances AI applications by providing richer context. This removes the need for auxiliary vector stores and simplifies pipelines.
Read more on how CrateDB handles vector data modeling for real-time analytics.
Columnar Database
Columnar databases speed up analytical queries by storing data in columns rather than rows, making operations like aggregations and scans much faster. They are the backbone of many OLAP workloads.
A hybrid system that offers both row based and columnar storage gives teams the best of both worlds: fast ingestion and fast analytics without maintaining two separate engines.
To understand the fundamentals, read our columnar database guide. For a deeper look at architectural trade-offs, see how columnar databases behave in real-time analytics workloads.
IoT Database
IoT platforms produce high frequency device telemetry with unpredictable schema changes. Traditional databases often struggle with the scale, velocity, and variability of this data.
A unified, distributed cluster absorbs high throughput streams, adapts to flexible structures, and runs real time analytics across devices and locations. This avoids relying on an IoT-specific database that limits analytical depth.
To explore the core requirements, read our IoT database guide. For a concrete example of how this approach works in production, read why CrateDB is a strong fit for IoT workloads.
AI Database
AI workloads depend on many data modalities: training datasets, inference history, vector embeddings, metadata, and features for online models. Storing these in different systems creates friction.
An AI database that blends vectors, structured data, JSON, text, and time series gives AI pipelines a single source of truth. The result is simpler context retrieval and more powerful hybrid search.
Big Data Database
Big data databases were built for horizontal scale, distributed storage, and handling vast volumes often processed through batch frameworks. These systems are powerful but often complex to operate.
A distributed SQL database achieves similar scale with far less overhead, letting teams run large analytical workloads in real time without introducing additional compute layers or external processing engines.
Data Historian
Data historians capture long term operational data, especially in industrial environments where sensor readings must be preserved for decades. They are critical in manufacturing, energy, and utilities.
Modern time series storage paired with SQL analytics enables organizations to keep their historian data while extending it with AI use cases, cloud access, and richer analytical capabilities.
Distributed Database
Distributed databases solve the scalability and resilience challenges that traditional single node systems cannot. They make it possible to spread workloads across multiple machines and avoid single points of failure.
A unified distributed engine brings these advantages directly into the analytics, search, and ingestion layers, reducing the need for custom distribution logic or additional operational systems.
Read more on how CrateDB's distributed database architecture.
Log Database
Log databases are optimized for storing and searching large volumes of text based logs used in observability, security, and troubleshooting workflows. They often require fast indexing and flexible query patterns.
By ingesting logs alongside metrics, JSON documents, and vectors, a unified engine enables more complete incident analysis and avoids the operational cost of maintaining a separate log-centric system.
Full Text Search Engine
Full text search engines specialize in indexing and ranking unstructured text to support keyword search, relevance scoring, and linguistic analysis. They excel in document-rich applications.
With integrated text indexing and search capabilities, a unified database lets teams combine free text queries with filters, joins, geospatial constraints, or even vector similarity to build more powerful retrieval workflows.
Read more on how CrateDB can be used as a full text search engine.
As data workloads continue to overlap and evolve, relying on a growing collection of specialized databases creates friction that slows teams down. Each category exists for a good reason, but modern applications rarely fit neatly into a single model. A unified real time analytics database offers a practical middle path. It preserves the strengths of these established technologies while reducing operational sprawl, simplifying pipelines, and enabling richer insights by keeping diverse data types together. Instead of designing around infrastructure limitations, engineering teams can focus on building products, accelerating AI adoption, and acting on fresh data the moment it arrives.


