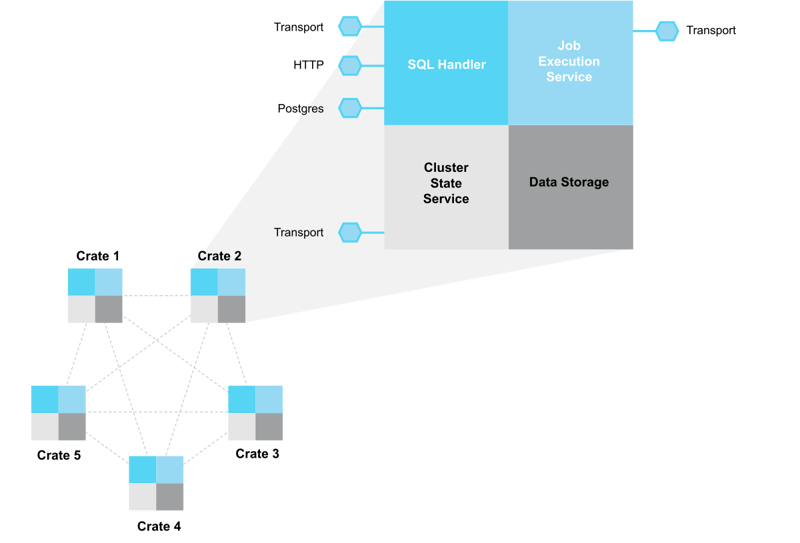
A fully symmetric cluster
CrateDB doesn’t rely on dedicated master or replica roles. Each node is equally capable and configured in the same way and can:
- Accept SQL queries or writes
- Act as a query coordinator (= handler node)
- Store and retrieve data from its local shards
- Communicate with other nodes through the transport layer
This symmetry allows CrateDB to balance load automatically, recover gracefully from node failures, and maintain performance as data and workloads grow.

Node communication and ports
Every CrateDB node exposes three main interfaces for interaction and coordination:
| Port | Function | Description |
|---|---|---|
| HTTP / REST | SQL and admin requests | Accepts SQL queries and management commands via HTTP. |
| PostgreSQL Wire Protocol | Application connectivity | Allows direct integration with PostgreSQL-compatible tools and drivers. |
| Transport Protocol | Cluster communication | Used internally for node discovery, data exchange, and job coordination. |
This multi-port design ensures high compatibility with external tools while maintaining efficient internal coordination across the cluster.
Inside a CrateDB node
Each node in the cluster contains four key components that work together to process and manage data efficiently:
SQL Handler: The SQL Handler is the node’s entry point for all incoming queries. It parses SQL statements, validates syntax, and generates an optimized execution plan. For distributed queries, it decides how to parallelize tasks across the cluster.
Job Execution Service: Once an execution plan is ready, it’s sent to the Job Execution Service, which manages and distributes the execution as one or more “jobs.” Each job may involve multiple tasks (filters, aggregations, joins) executed locally or remotely.
These jobs are coordinated using the Transport Protocol, enabling real-time parallel execution across all nodes.
Cluster State Service: At the heart of every CrateDB cluster is the Cluster State Service, responsible for maintaining global state and coordination. It manages:
- Node discovery and membership
- Master node election (for cluster metadata only)
- Shard allocation and rebalancing
- Cluster health monitoring
This service ensures that the cluster remains consistent, resilient, and self-healing, even as nodes join, leave, or recover.
Data Storage Component: Each node’s storage engine manages local data and indexing. CrateDB stores data in sharded tables, with each shard represented as a Lucene index on disk. This allows fast access, advanced full-text search, and fine-grained indexing without external components. Each node reads and writes data locally, which keeps operations fast and network-efficient, key to CrateDB’s real-time query performance.
How it all comes together
When a query is received:
- The handler node (the one receiving the query) parses it and creates an execution plan.
- It distributes relevant operations to data nodes where the required shards reside.
- Each data node executes its part of the plan locally and returns partial results.
- The coordinator node aggregates these results and returns the final dataset to the client.
