Our OSCON Demo: A GitHub and IBM Watson Powered Slack Bot
Building a Slackbot that answers questions about project data in the Github Archive. Powered by CrateDB and IBM Watson API.

Building a Slackbot that answers questions about project data in the Github Archive. Powered by CrateDB and IBM Watson API.
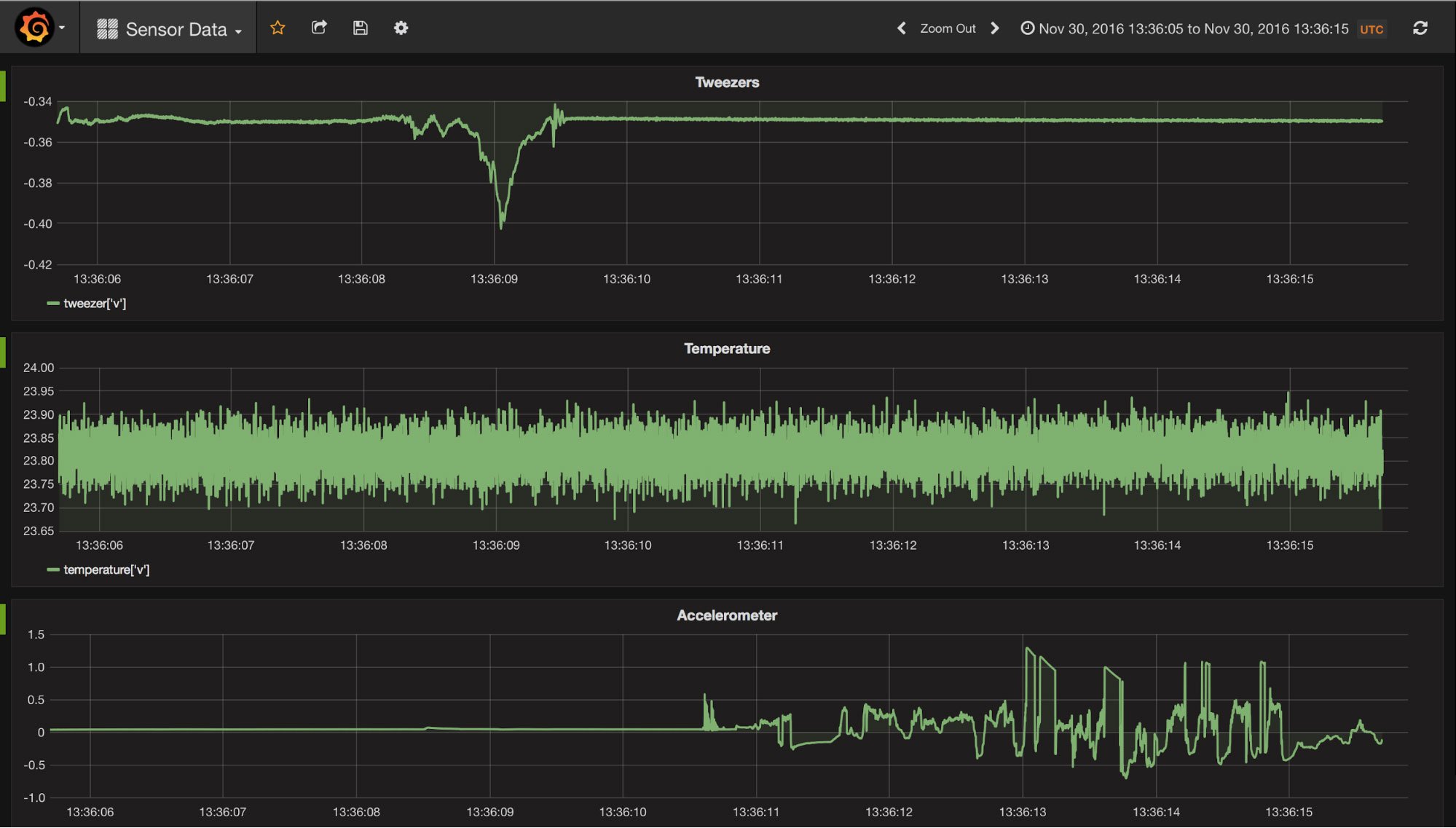
How to use CrateDB and Grafana to create scalable and fast dashboards.
How to orchestrate the deployment and scaling of a shared-nothing SQL database (CrateDB) on Docker 1.12 using Docker Swarm mode.

During the Endocode's Kubernetes birthday party on 21 July, we came up with the idea to kickstart our Kubernetes support with a Hackathon!
Another great project from Snow Sprint, Cr8, a selection of utility scripts for working with Crate clusters.
A blog post about my experiments importing 236 million rows of data of the german weather service, DWD, into Crate.
How you get started running CrateDB on Linux and Windows with Azure.
The Crate Driver supports all latest versions of Laravel, and eloquent, Laravel's ORM system.
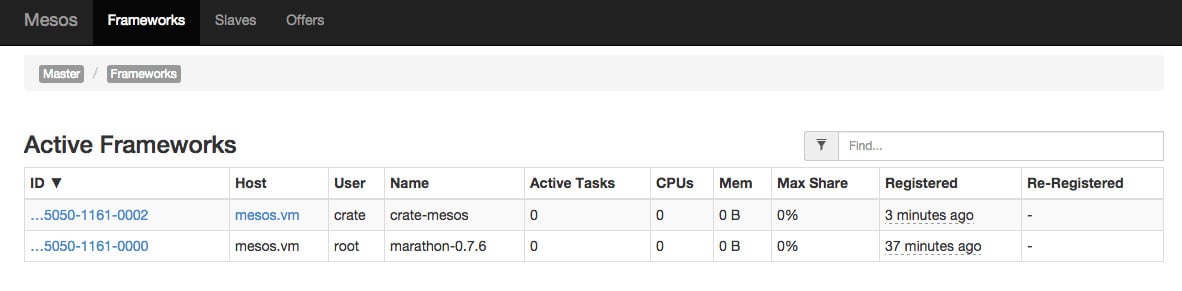
How to get started running and managing CrateDB databases with Mesos.
In this tutorial post will demonstrate how to integrate Spring Data Crate with your Java application based on a very simple Spring Boot REST application...