How CrateDB Works
Time-series data: CrateDB handles high-volume time series data, enabling fast trend analysis, monitoring, and real-time insights based on when events occur.
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
Learn more >
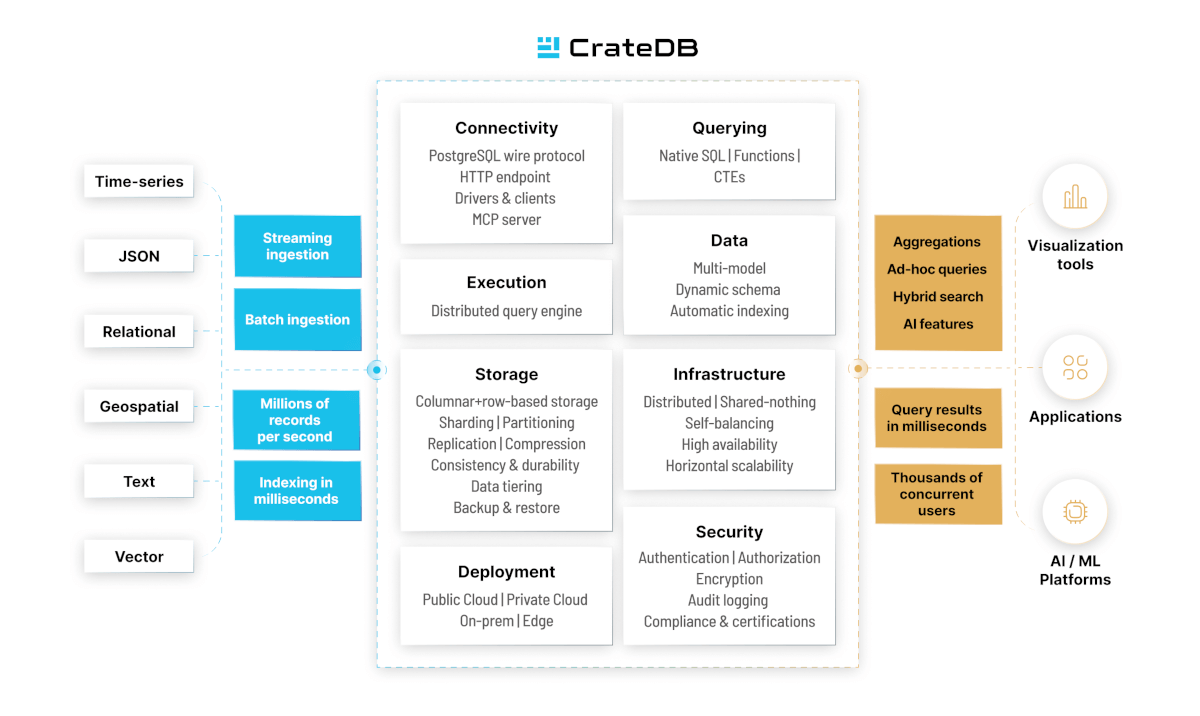
All data types, one SQL engine
Time-series, JSON, relational, geospatial, full-text, and vector data are all first-class citizens in CrateDB. Query across all of them in a single statement; no separate pipelines, no synchronization overhead, no storage layer per type.
Ingestion at any velocity
CrateDB ingests millions of records per second from streaming sources, batch imports, and everything in between. Data is indexed automatically on arrival and queryable within milliseconds. No manual indexing step, no batch delay before you can query fresh data.
Standard SQL, no new language to learn
CrateDB uses standard SQL throughout — joins, aggregations, subqueries, CTEs, and user-defined functions. The PostgreSQL wire protocol means your existing tools, drivers, and BI platforms connect without modification.
Infrastructure that manages itself
CrateDB runs on a shared-nothing architecture where every node is equal. The cluster self-balances as data grows, detects and recovers from node failures automatically, and scales horizontally without downtime. Add nodes while the database stays live.
Security and compliance
Authentication, role-based access control, encryption at rest and in transit, and audit logging are built into every deployment. CrateDB Cloud is ISO 27001 certified on AWS and Azure.
Deploy on your terms
CrateDB runs the same way everywhere. Use CrateDB Cloud for a fully managed service on AWS, Azure, or GCP — operated by the engineers who built it. Deploy on your own infrastructure with CrateDB Enterprise for on-premises, private cloud, or edge environments. Or start with the open-source edition and self-manage. The same database, the same SQL, across all three models.
Support when it matters
CrateDB Cloud subscriptions include Standard support. Monitoring, operations, and direct access to the team that built the database are all included. Upgrade to Premium support for contractual SLAs, a dedicated Customer Success Manager, and hands-on engineering expertise for optimization and cost management.
For self-managed deployments, Standard and Premium support plans are available with the same SLA and CSM options.
CrateDB Academy – Free Courses
Enroll for free, Learn, and Get Certified
CrateDB Architecture Guide

CrateDB Architecture Guide
This comprehensive guide covers all the key concepts you need to know about CrateDB's architecture. It will help you gain a deeper understanding of what makes it performant, scalable, flexible and easy to use. Armed with this knowledge, you will be better equipped to make informed decisions about when to leverage CrateDB for your data projects.
Want to Explore Further?
What CrateDB Users Say
Latest Release Announcements

New Release: CrateDB 6.4
2026-07-20The most recent CrateDB version has been released as CrateDB 6.4. The focus for this development cycle has been on performance and resilience of everyday operations, alongside a steady stream of ...

New release: CrateDB 6.3
2026-05-20The most recent CrateDB version has been released as CrateDB 6.3. The focus for the development cycle has been on compatibility to make it easier to integrate with 3rd party tools. As always, CrateDB ...

New release: CrateDB 6.2
2026-02-09A new feature release of CrateDB, version 6.2, has been released today. This release focuses on PostgreSQL compatibility and operational maturity: featuring CREATE/DROP SCHEMA, UUID datatype, ...