The updated data, including the new attribute, can be instantly viewed and filtered with a SELECT query like in Example 1.
This approach ensures high query performance and adaptability to different data types. Indexing strategies are tailored accordingly and can be turned off on specific fields when needed. With automatic indexing, CrateDB optimizes resource utilization, allowing users to focus on deriving insights rather than managing indexing complexities.
Columnar Storage
CrateDB uses columnar storage, which stores data table columns separately, as opposed to row-based storage which stores entire rows together. This offers several advantages for time series data:
- Efficient data scanning: Only relevant columns are read from storage for queries, aggregations, and sort operations.
- Better compression: Similar data types in each column allow for effective compression techniques.
- Improved memory handling: Fast reads for frequently accessed columns are enabled via memory-mapped columnar storage files.
 In our example, the columnar store links record IDs to temperatures at each weather station. When aggregating, such as when calculating the average temperature, CrateDB accesses the 'temperature' column's values directly, speeding up the query execution.
In our example, the columnar store links record IDs to temperatures at each weather station. When aggregating, such as when calculating the average temperature, CrateDB accesses the 'temperature' column's values directly, speeding up the query execution.
This method is ideal for time-series data, where datasets are large and queries often involve time interval aggregations. Fast range scans, even when combined with additional filters, make this approach highly efficient.
Block KD-Trees
Inverted Index and Full-text Index
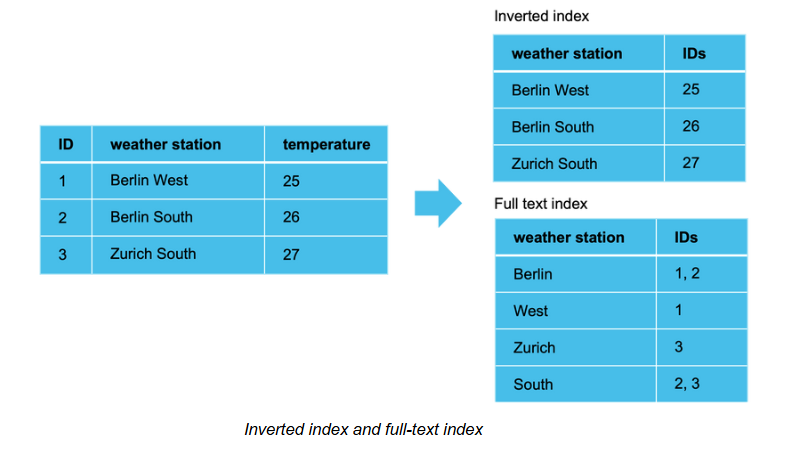
For more complex searches, a full-text index supports searches for partial matches and variations. In the illustration above, the term 'Berlin' is linked to IDs 1 and 2, corresponding to ‘Berlin West' and ‘Berlin South'. This allows users to search for a term like ‘Berlin' and find all related stations in Berlin, regardless of their exact names.
Full-text search in CrateDB, extending beyond simple pattern matching, is enabled by creating full-text indexes, including composite indexes for indexing multiple text columns together.
In this example, a composite full-text index on the 'name' and 'description' columns can be used to perform sophisticated searches. Custom analyzers allow for tailored text tokenization processes suitable for different languages or specific needs. In a typical use case, a full-text search is conducted on the 'stations' table to locate key weather stations using the term 'key station' in the name or description field.
 Results are ranked based on relevance, indicating how closely each entry matches the search term.
Results are ranked based on relevance, indicating how closely each entry matches the search term.
CrateDB's use of standard SQL simplifies full-text search integration with other filter types and query criteria. It supports, amongst others, fuzzy searches, phrase searches, and attribute boosting, enhancing result relevance. These features enable efficient handling of advanced time series use cases, including data filtering, slicing, and complex searches.
HNSW (Hierarchical Navigable Small World) Index
The Hierarchical Navigable Small World (HNSW) indexing in CrateDB is highly efficient for managing high-dimensional vectors. It's crucial for executing approximate nearest neighbour searches, also known as similarity searches.
HNSW excels at managing and interpreting unstructured data like text, video, and audio, often found in AI applications. This algorithm is used to create vector indexes, which greatly improve query speed.
