Query optimization is fundamental for dealing with large-scale, time-series data, ensuring efficient data retrieval, storage, and improved overall performance.
Index Use for Query Performance
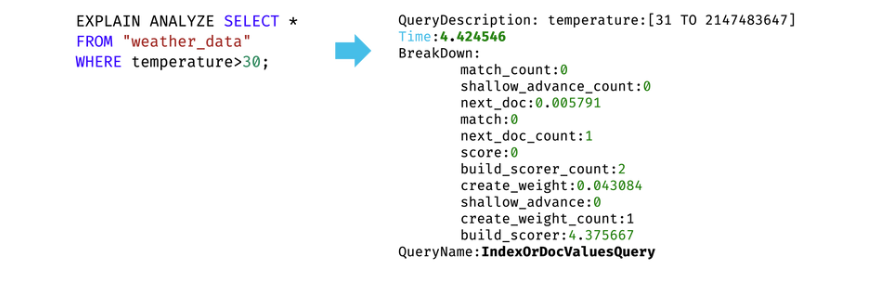
Query Execution Plan Analysis
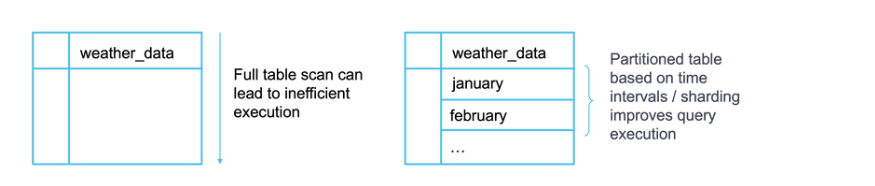
Parallel Execution with Partitioning and Sharding
Arrays for Storage Optimization
In CrateDB, arrays are an effective solution for optimizing storage. They allow storing multiple values in a single structure and are particularly useful for handling large-scale time-series data. Arrays allow for efficient representation of data sets and can significantly reduce the storage footprint. They can store sequences of measurements, reducing the need for individual records for each data point. By restructuring data into arrays, applying compression algorithms, and turning off indexes on array fields, storage requirements can be significantly reduced. Depending on the particular data model, we see a reduction in disk space used by more than 80%.
JOIN Optimization with Common Table Expressions
Common Table Expressions (CTEs) enhance both the performance and readability of queries. Particularly useful in complex scenarios needing many filtering and aggregation steps, or when a data subset is repeatedly used within one query, CTEs can offer considerable performance benefits over traditional JOIN operations. Each subsequent JOIN operation is refined to the smallest possible dataset, leading to faster query performance and efficient resource use.

