CrateDB Cloud Regions for AWS, Azure and GCP
Explore CrateDB Cloud's availability across AWS, Azure, and GCP regions, and learn how your feedback can influence future expansions. Deploy your free cluster today.

Explore CrateDB Cloud's availability across AWS, Azure, and GCP regions, and learn how your feedback can influence future expansions. Deploy your free cluster today.

Learn how CrateDB revolutionizes database management with automatic indexing on every column, simplifying queries and boosting performance without upfront schema planning.

New CrateDB Cloud features are available: new left bar menus, integrated query console, and SQL job scheduler.
The introduction of BKD-tree-based indexing has brought notable enhancements in query performance (both indexing and lookup), streamlined index configuration and minimized storage demands.

Learn how to get started with CrateDB, with the best tutorials, from installation to logical replication!
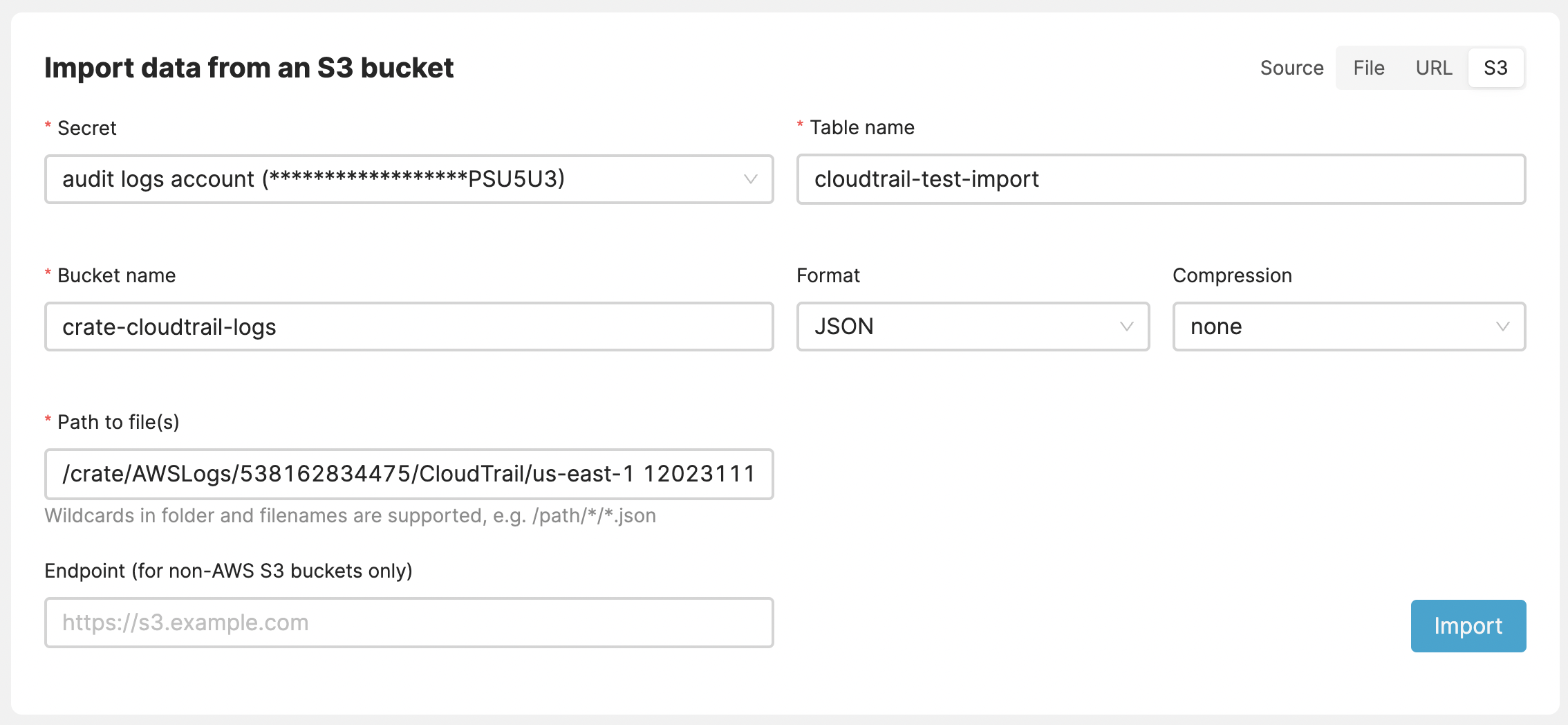
Simplify your data imports with Cloud's new support for globbing, easier to handle large volumes of data from services like Segment or AWS CloudTrail.
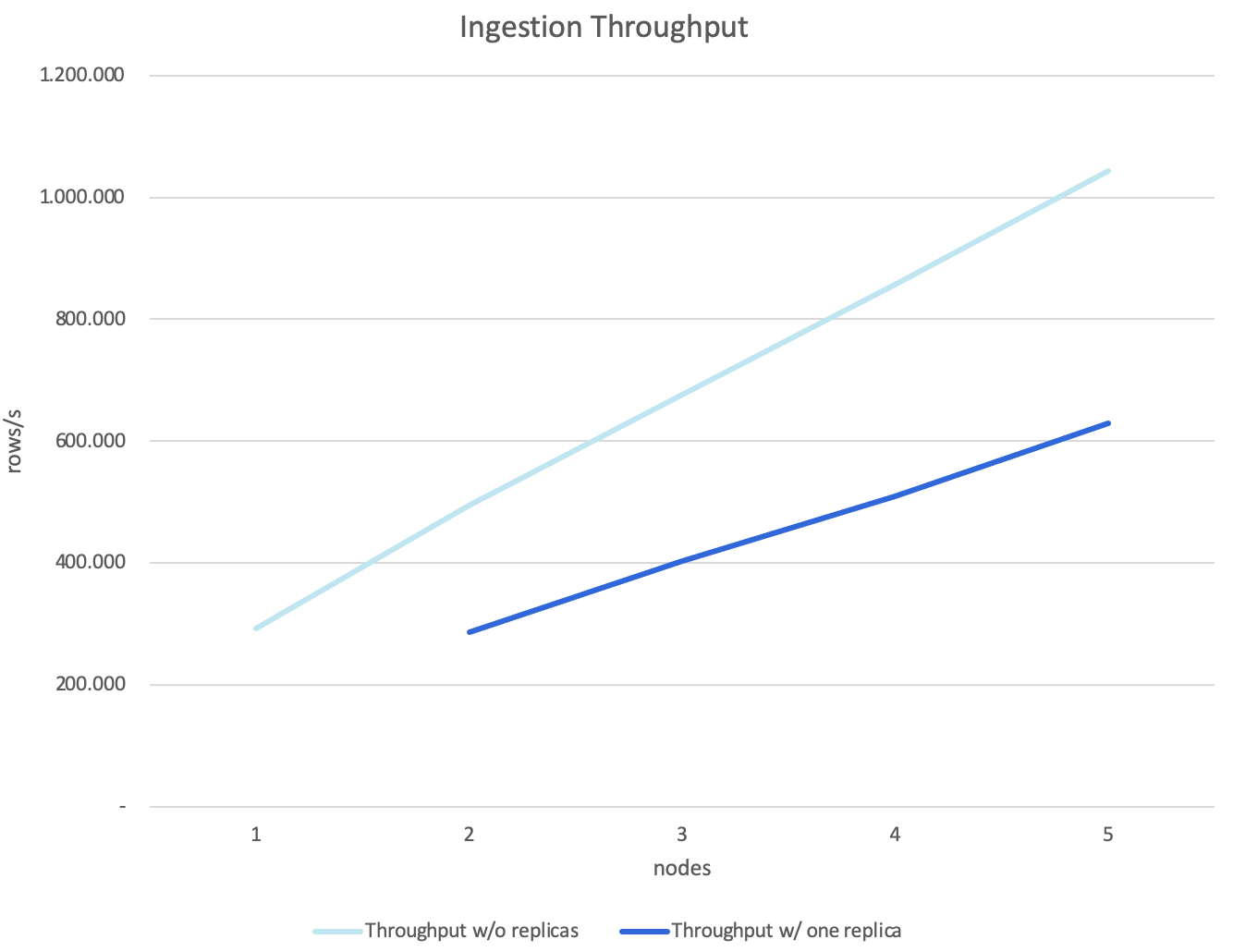
This post describes the process of scaling ingest throughput from a single node cluster to reaching 1 million rows per second.

Let's explore how to leverage the power of CrateDB in conjunction with Dask, to perform efficient data processing and analysis tasks!

Leverage the full potential of Apache Airflow with CrateDB, by Niklas Schmidtmer and Marija Selakovic from CrateDB's Customer Engineering team.

We couldn't be happier with the great talks we had in this 1-hour event! Check the highlights with Kooky, Metabase, and Apache Flink.