Clustering¶
The aim of this document is to describe, on a high level, how the distributed SQL database CrateDB uses a shared nothing architecture to form high- availability, resilient database clusters with minimal effort of configuration.
It will lay out the core concepts of the shared nothing architecture at the heart of CrateDB. The main difference to a primary-secondary architecture is that every node in the CrateDB cluster can perform every operation - hence all nodes are equal in terms of functionality (see Components of a CrateDB Node) and are configured the same.
Table of contents
Components of a CrateDB Node¶
To understand how a CrateDB cluster works it makes sense to first take a look at the components of an individual node of the cluster.
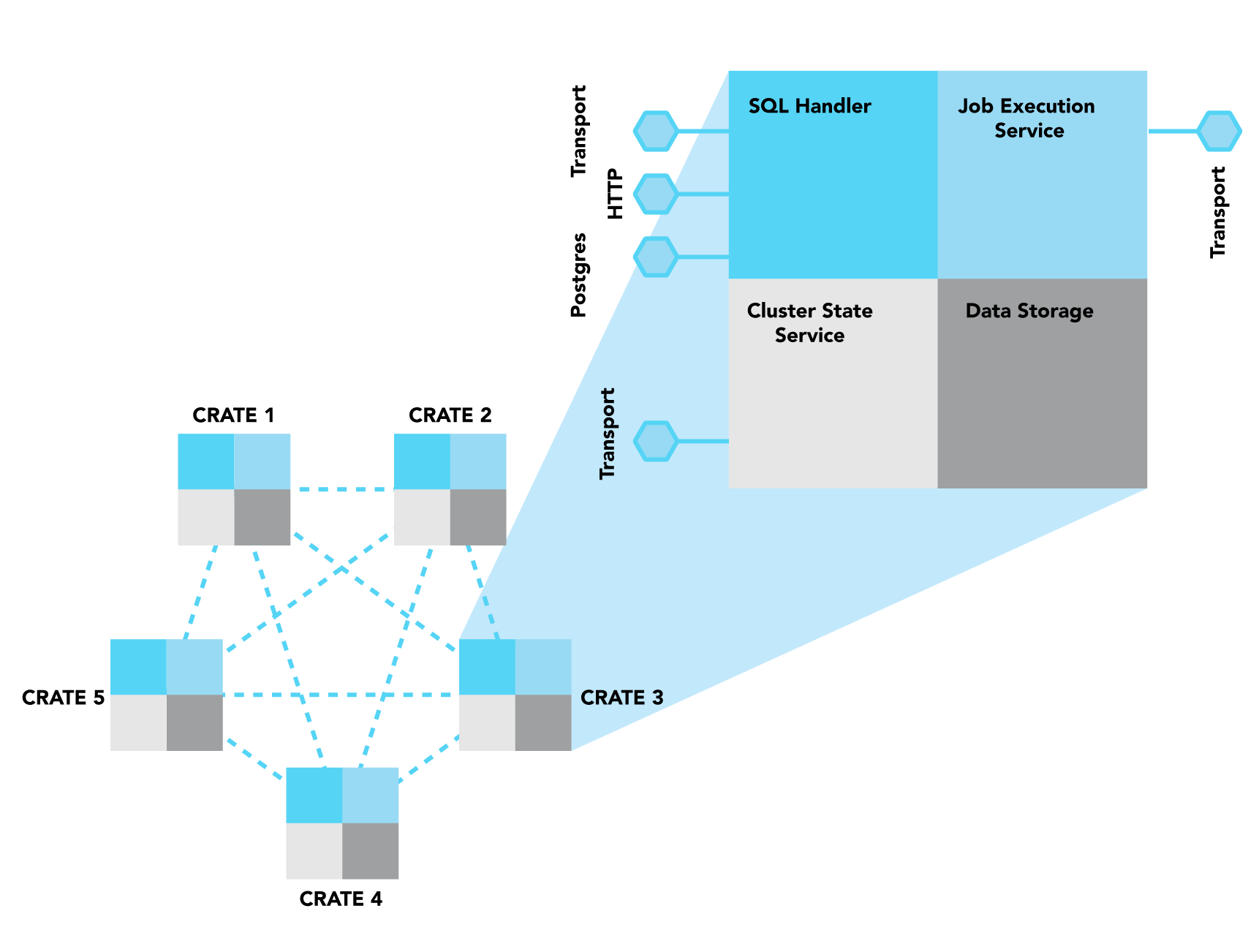
Figure 1¶
Multiple interconnected instances of CrateDB form a single database cluster. The components of each node are equal.
Figure 1 shows that in CrateDB each node of a cluster contains the same components that (a) interface with each other, (b) with the same component from a different node and/or (c) with the outside world. These four major components are: SQL Handler, Job Execution Service, Cluster State Service, and Data Storage.
SQL Handler¶
The SQL Handler part of a node is responsible for three aspects:
handling incoming client requests,
parsing and analyzing the SQL statement from the request and
creating an execution plan based on the analyzed statement (abstract syntax tree)
The SQL Handler is the only of the four components that interfaces with the “outside world”. CrateDB supports three protocols to handle client requests:
HTTP
a Binary Transport Protocol
the PostgreSQL Wire Protocol
A typical request contains a SQL statement and its corresponding arguments.
Job Execution Service¶
The Job Execution Service is responsible for the execution of a plan (“job”). The phases of the job and the resulting operations are already defined in the execution plan. A job usually consists of multiple operations that are distributed via the Transport Protocol to the involved nodes, be it the local node and/or one or multiple remote nodes. Jobs maintain IDs of their individual operations. This allows CrateDB to “track” (or for example “kill”) distributed queries.
Cluster State Service¶
The three main functions of the Cluster State Service are:
cluster state management,
election of the master node and
node discovery, thus being the main component for cluster building (as described in section Multi-node setup: Clusters).
It communicates using the Binary Transport Protocol.
Data storage¶
The data storage component handles operations to store and retrieve data from disk based on the execution plan.
In CrateDB, the data stored in the tables is sharded, meaning that tables are divided and (usually) stored across multiple nodes. Each shard is a separate Lucene index that is stored physically on the filesystem. Reads and writes are operating on a shard level.
Multi-node setup: Clusters¶
A CrateDB cluster is a set of two or more CrateDB instances (referred to as nodes) running on different hosts which form a single, distributed database.
For inter-node communication, CrateDB uses a software specific transport protocol that utilizes byte-serialized Plain Old Java Objects (POJOs) and operates on a separate port. That so-called “transport port” must be open and reachable from all nodes in the cluster.
Cluster state management¶
The cluster state is versioned and all nodes in a cluster keep a copy of the latest cluster state. However, only a single node in the cluster – the master node – is allowed to change the state at runtime. This node is elected by all nodes in the cluster.
Settings, metadata, and routing¶
The cluster state contains all necessary meta information to maintain the cluster and coordinate operations:
Global cluster settings
Discovered nodes and their status
Schemas of tables
The status and location of primary and replica shards
When the master node updates the cluster state it will publish the new state to all nodes in the cluster and wait for all nodes to respond before processing the next update.
Master Node Election¶
The process of electing a node as the master node in a cluster is called Master Node Election. There must be only one master node per cluster at any single time. In a CrateDB cluster any node is eligible to be elected as a master node, although this could also be restricted to a subset of nodes if required. These nodes will then elect a single node as master to coordinate the cluster state across the cluster.
Note
The following only applies to CrateDB versions 3.x and below. CrateDB versions 4.x and above determine quorum size automatically.
A minimum number of nodes (referred as a quorum) needs to configured (using the discovery.zen.minimum_master_nodes setting) to ensure that in case of a network partition (when some nodes become unavailable) the cluster can elect a master node.
If the quorum is smaller than half the expected nodes in the cluster, and the cluster is split in half by a network partition, neither partition will be able to elect a new master node.
If the quorum is exactly half the expected nodes in the cluster, and the cluster is split in half, both sides of the partition will be able to elect a master node. This is known as a split-brain scenario, and can lead to data loss because the master nodes may disagree with each other when the full cluster is restored.
To avoid both of these problems, the quorum must be greater than half the expected nodes in the cluster:
q = FLOOR(n / 2) + 1
It also helps if your cluster has an odd nodes. That way, no matter how the cluster gets split, one side of the split will be able to elect a master node.
For example: a five node cluster should have a quorum set at three. The largest network partition would split the cluster into three nodes and two nodes. In this scenario, the three node cluster would elect a master node and the two node cluster would not.
Discovery¶
The process of finding, adding and removing nodes is done in the discovery module.

Figure 2¶
Phases of the node discovery process. n1 and n2 already form a cluster where n1 is the elected master node, n3 joins the cluster. The cluster state update happens in parallel!
Node discovery happens in multiple steps:
CrateDB requires a list of potential host addresses for other CrateDB nodes when it is starting up. That list can either be provided by a static configuration or can be dynamically generated, for example by fetching DNS SRV records, querying the Amazon EC2 API, and so on.
All potential host addresses are pinged. Nodes which receive the request respond to it with information about the cluster it belongs to, the current master node, and its own node name.
Now that the node knows the master node, it sends a join request. The Primary verifies the incoming request and adds the new node to the cluster state that now contains the complete list of all nodes in the cluster.
The cluster state is then published across the cluster. This guarantees the common knowledge of the node addition.
Caution
If a node is started without any initial_master_nodes or a discovery_type
set to single-node (e.g., the default configuration), it will never join
a cluster even if the configuration is subsequently changed.
It is possible to force the node to forget its current cluster state by using the crate-node CLI tool. However, be aware that this may result in data loss.
Networking¶
In a CrateDB cluster all nodes have a direct link to all other nodes; this is known as full mesh topology. Due to simplicity reasons every node maintains a one-way connections to every other node in the network. The network topology of a 5 node cluster looks like this:
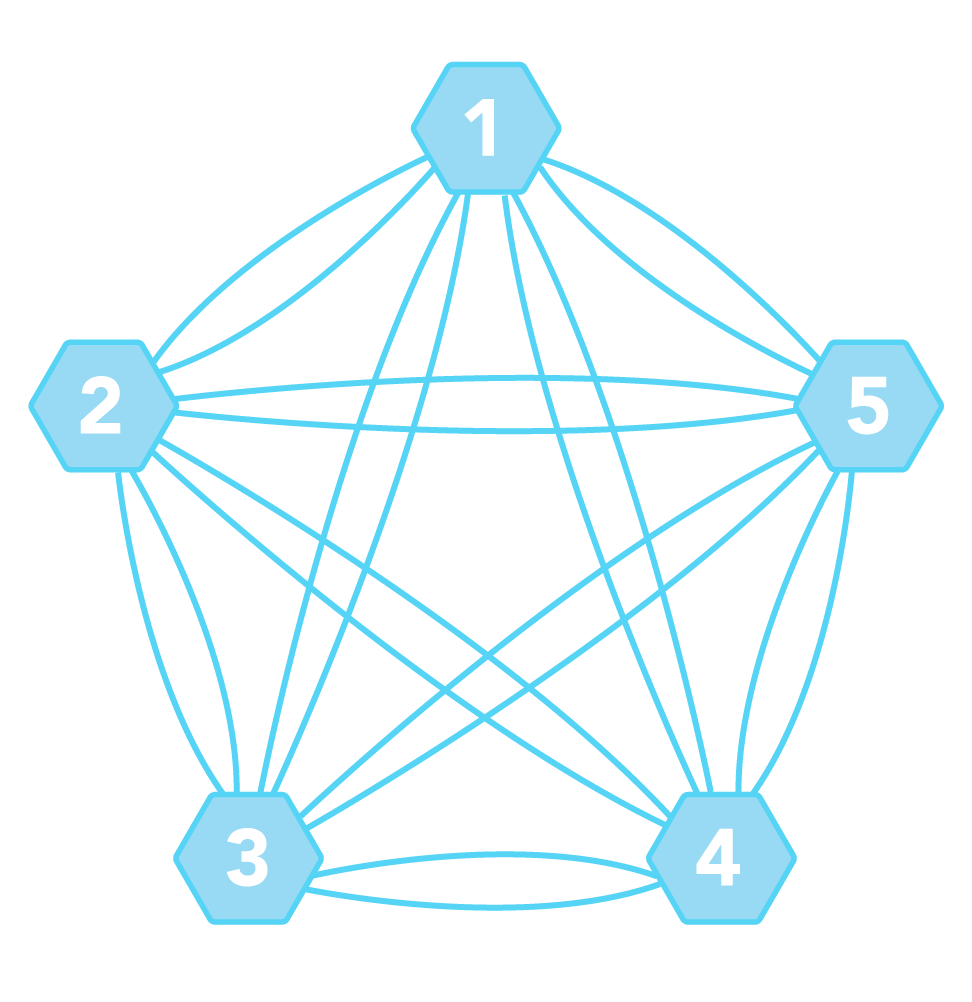
Figure 3¶
Network topology of a 5 node CrateDB cluster. Each line represents a one-way connection.
The advantages of a fully connected network are that it provides a high degree of reliability and the paths between nodes are the shortest possible. However, there are limitations in the size of such networked applications because the number of connections (c) grows quadratically with the number of nodes (n):
c = n * (n - 1)
Cluster behavior¶
The fact that each CrateDB node in a cluster is equal allows applications and users to connect to any node and get the same response for the same operations. As already described in section Components of a CrateDB Node, the SQL handler is responsible handling incoming client SQL requests, either using the HTTP, transport protocol or PostgreSQL wire protocol. The “handler node” that accepts the client request also returns the response to the client. It does neither redirect nor delegate the request to a different nodes. The handler node parses the incoming request into a syntax tree, analyzes it and creates an execution plan locally. Then the operations of the plan are executed in a distributed manner. The upstream of the final phase of the execution is always the handler which then returns the response to the client.
Application use case¶
In a conventional setup of an application using a primary-secondary database the deployed stack looks similar to this:
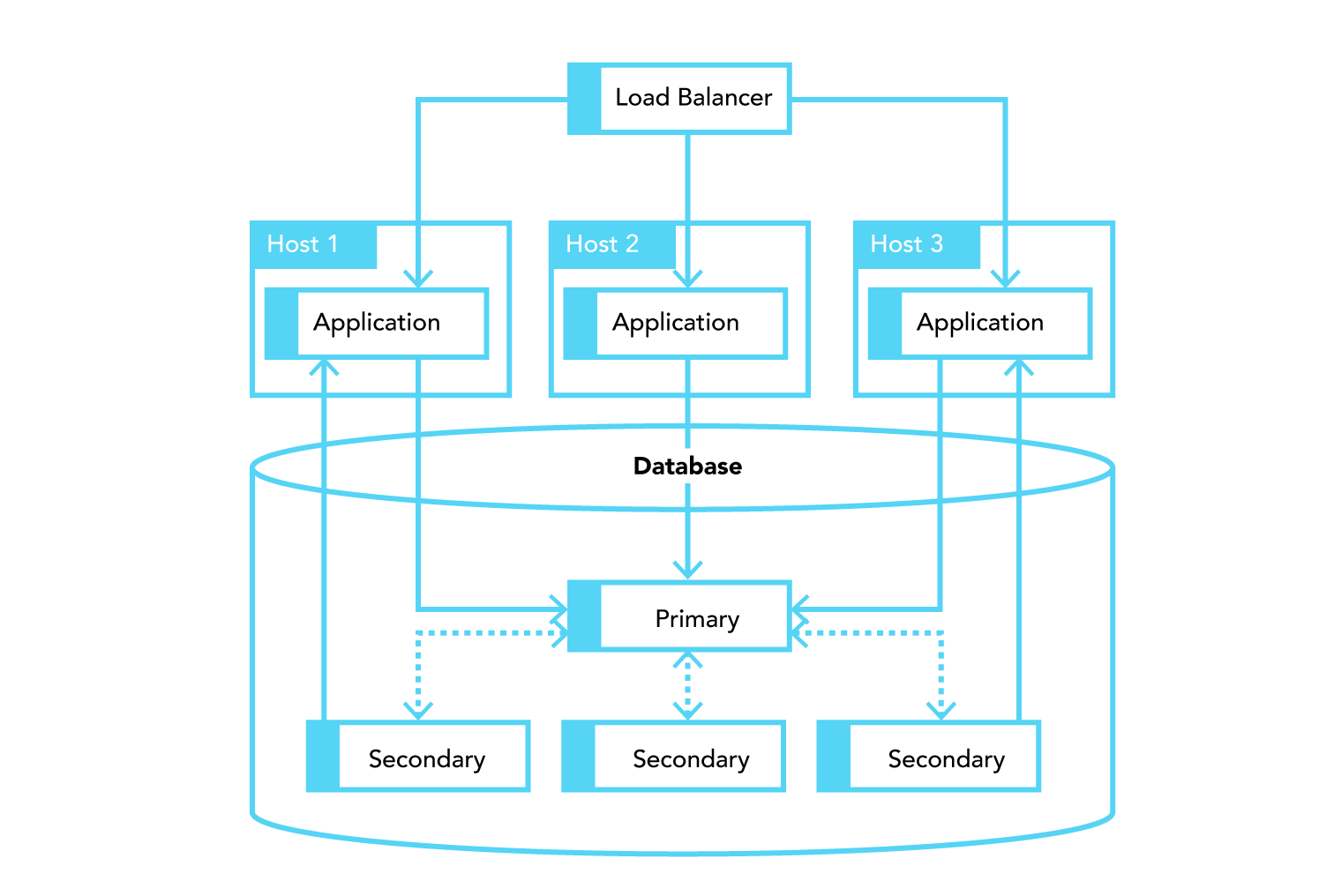
Figure 4¶
Conventional deployment of an application-database stack.
However, this given setup does not scale because all application servers use the same, single entry point to the database for writes (the application can still read from secondaries) and if that entry point is unavailable the complete stack is broken.
Choosing a shared nothing architecture allows DevOps to deploy their applications in an “elastic” manner without SPoF. The idea is to extend the shared nothing architecture from the database to the application which in most cases is stateless already.
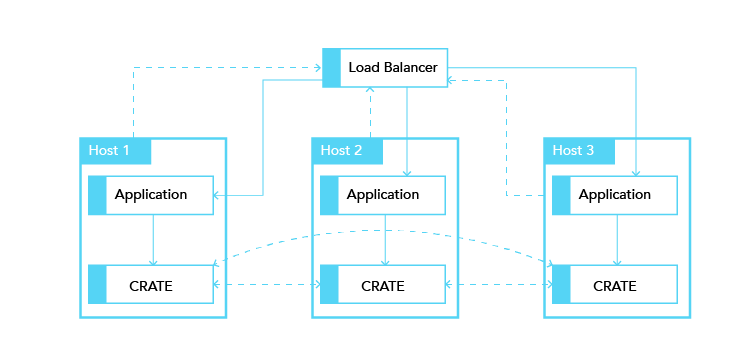
Figure 5¶
Elastic deployment making use of the shared nothing architecture.
If you deploy an instance of CrateDB together with every application server you will be able to dynamically scale up and down your database backend depending on your needs. The application only needs to communicate to its “bound” CrateDB instance on localhost. The load balancer tracks the health of the hosts and if either the application or the database on a single host fails the complete host will taken out of the load balancing.