Flink¶
![]()

Apache Flink is a programming framework and distributed processing engine for stateful computations over unbounded and bounded data streams, written in Java. It is a battle-hardened stream processor widely used for demanding real-time applications.
Details
Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale. It received the 2023 SIGMOD Systems Award.
Apache Flink greatly expanded the use of stream data-processing. Data Pipelines Done Right.
Managed Flink
A few companies are specializing in offering managed Flink services.
Aiven offers their managed Aiven for Apache Flink solution.
Immerok Cloud’s offering is being converged into Flink managed by Confluent, see Confluent Streaming Data Pipelines.
Connect¶
Flink’s JdbcSink is a streaming connector that writes data to a JDBC database, for example using the [PostgreSQL JDBC Driver] that also works with CrateDB. When configuring the data sink, use:
- url:
jdbc:postgresql://localhost:5432/crate- driver:
org.postgresql.Driver
Synopsis¶
from pyflink.common import Types
from pyflink.datastream.connectors.jdbc import JdbcConnectionOptions, JdbcExecutionOptions, JdbcSink
JdbcSink.sink(
"INSERT INTO doc.weather_flink_sink (location, current) VALUES (?, ?)",
Types.ROW_NAMED(["location", "current"], [Types.STRING(), Types.STRING()]),
JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.with_url("jdbc:postgresql://localhost:5432/crate")
.with_driver_name("org.postgresql.Driver")
.with_user_name("crate")
.with_password("")
.build())
More Examples
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
JdbcSink.sink(
"INSERT INTO my_schema.books (id, title, authors, year) VALUES (?, ?, ?, ?)",
(statement, book) -> {
statement.setLong(1, book.id);
statement.setString(2, book.title);
statement.setString(3, book.authors);
statement.setInt(4, book.year);
},
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:postgresql://localhost:5432/crate")
.withDriverName("org.postgresql.Driver")
.withUsername("crate")
.withPassword("")
.build()
));
from pyflink.common import Types
from pyflink.datastream.connectors.jdbc import JdbcConnectionOptions, JdbcExecutionOptions, JdbcSink
JdbcSink.sink(
"INSERT INTO doc.weather_flink_sink (location, current) VALUES (?, ?)",
Types.ROW_NAMED(["location", "current"], [Types.STRING(), Types.STRING()]),
JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.with_url("jdbc:postgresql://localhost:5432/crate")
.with_driver_name("org.postgresql.Driver")
.with_user_name("crate")
.with_password("")
.build(),
JdbcExecutionOptions.builder()
.with_batch_interval_ms(1000)
.with_batch_size(200)
.with_max_retries(5)
.build()
)
Learn¶
Guides
Learn how to build a data ingestion pipeline using three open-source tools: Apache Kafka, Flink, and CrateDB.
An executable stack with Apache Kafka, Apache Flink, and CrateDB. Uses Java.
An executable stack with Apache Kafka, Apache Flink, and CrateDB. Uses Python.
Webinars
Apache Flink 101
Why Flink is interesting for building real-time streaming applications, and how it works.
Flink’s performance and robustness are the results of a handful of core design principles, including a shared-nothing architecture with local state, event-time processing, and state snapshots (for recovery). This course introduces you to these core concepts.
Webinar Fundamentals
CrateDB Community Day: Maximizing your data potential with CrateDB integrations
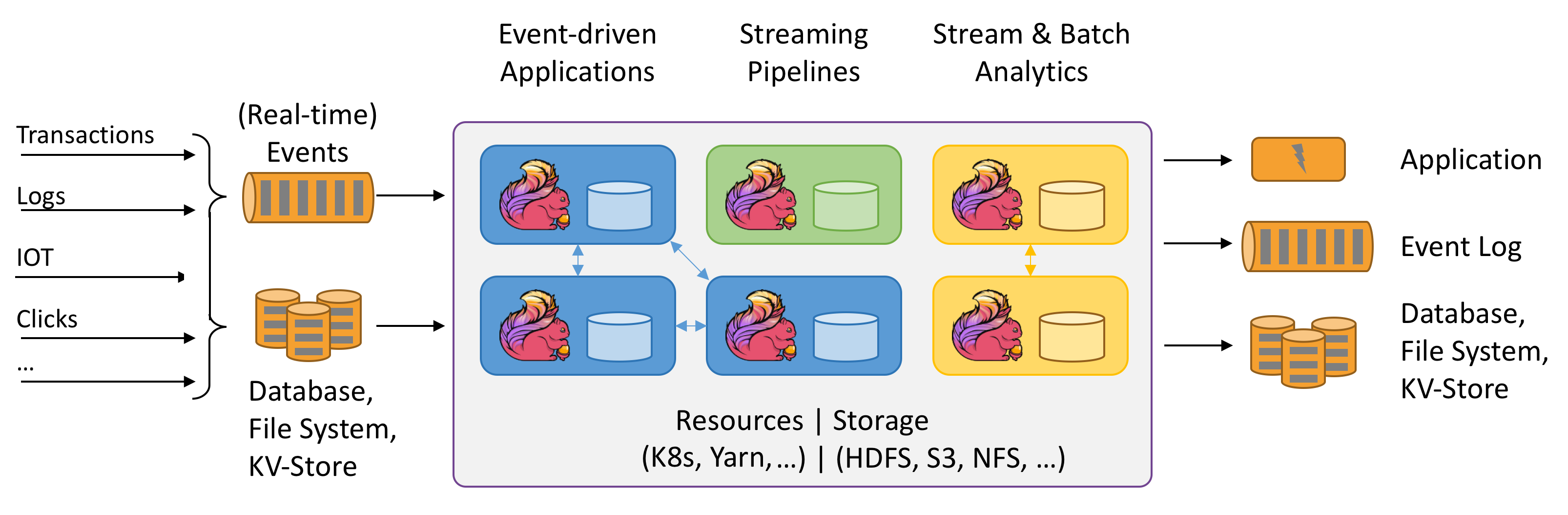
Flink connects different messaging systems, file systems, and database key/value stores for multiple purposes. For data integrations, it can serve as a data hub between systems and much more like event-driven applications, and it’s very flexible.
The webinar includes a live demo of Apache Flink with CrateDB as source or sink.
Webinar Integrations